University Notes - Computer Science
Just code and projects for university. All the study-related contents are just a summary of the actual material. For better explanations check other material here, study on books suggested by the teachers and learn by writing your own material 😀
You are encouraged to follow the lectures and do exercises over and over again. The process of learning requires effort
A pottery teacher split her class into two halves
To the first half she said, "You will spend the semester studying pottery, planning, designing, and creating your perfect pot. At the end of the semester, there will be a competition to see whose pot is the best".
To the other half she said, "You will spend your semester making lots of pots. Your grade will be based on the number of completed pots you finish. At the end of the semester, you'll also have the opportunity to enter your best pot into a competition."
The first half of the class threw themselves into their research, planning, and design. Then they set about creating their one, perfect pot for the competition.
The second half of the class immediately grabbed fistfulls of clay and started churning out pots. They made big ones, small ones, simple ones, and intricate ones. Their muscles ached for weeks as they gained the strength needed to throw so many pots.
At the end of class, both halves were invited to enter their most perfect pot into the competition. Once the votes were counted, all of the best pots came from the students that were tasked with quantity. The practice they gained made them significantly better potters than the planners on a quest for a single, perfect pot.
Original Post
Un'occhiata veloce a GitHub Classroom
Sarò molto sintetico, solo per dare un'idea di come funzionano gli esercizi e il feedback agli studenti
Home
Creare una "Classroom"
Per creare una "Classroom" bisogna selezionare l'organizzazione nella quale si vogliono mettere i repository (si quelli con le soluzioni degli studenti, sia i template con i test)
Una possibile organizzazione per il corso potrebbe essere "Metodologie di programmazione Sapienza"
Passiamo direttamente alle informazioni importanti
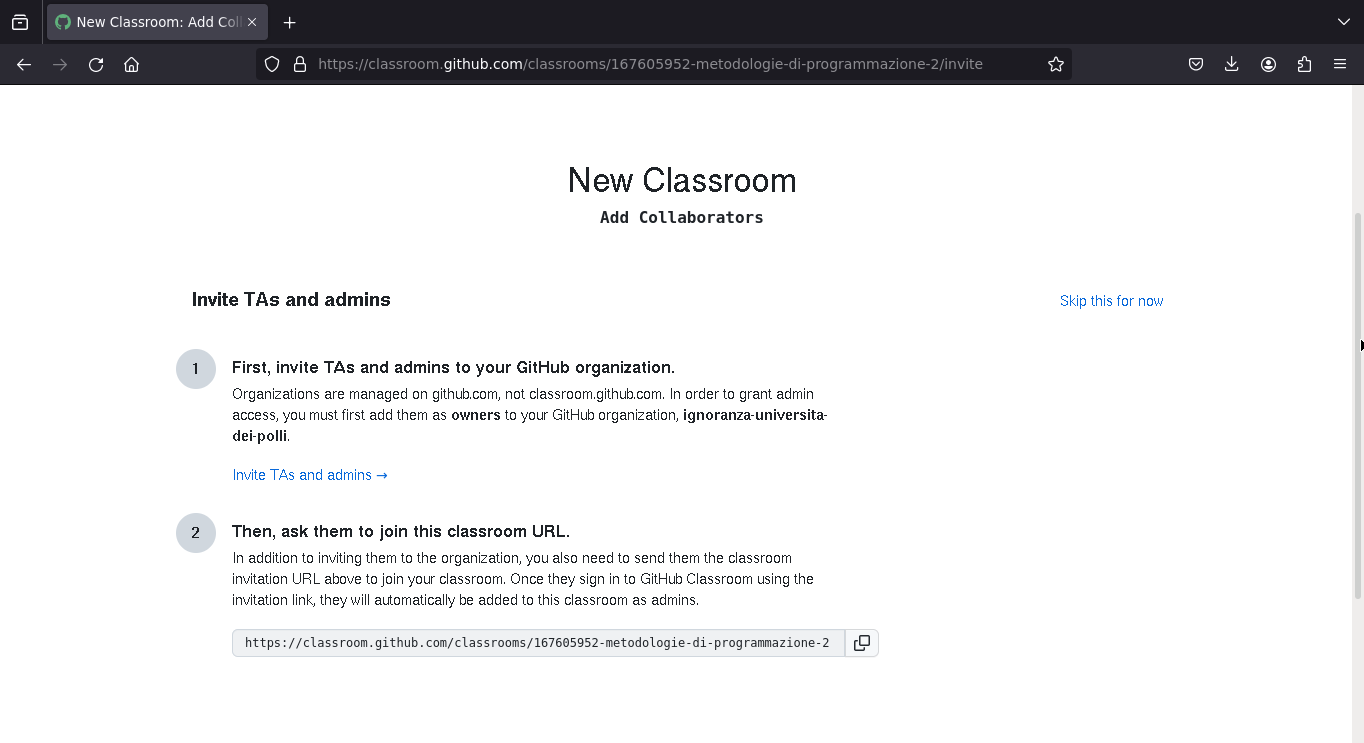
Amministratori della "Classroom"
Si può usare un link d'invito per decidere i docenti (amministratori) del corso
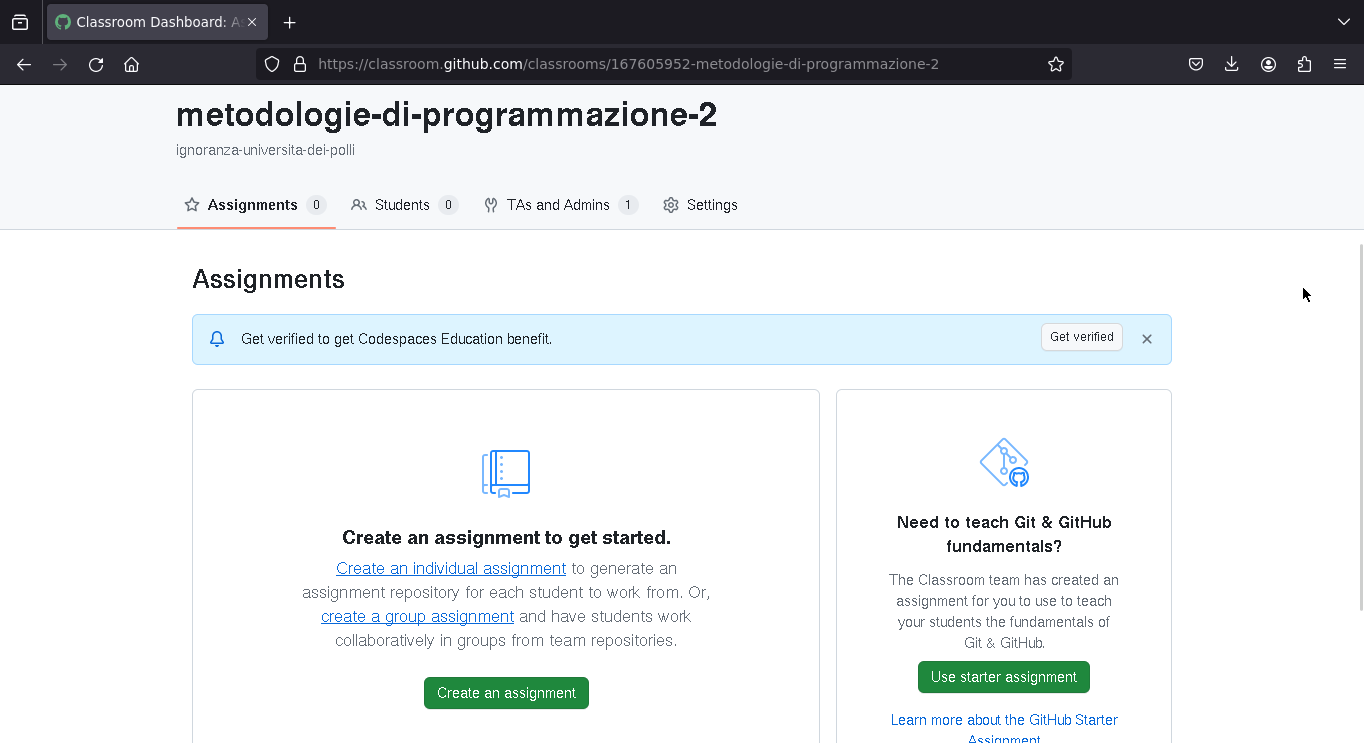
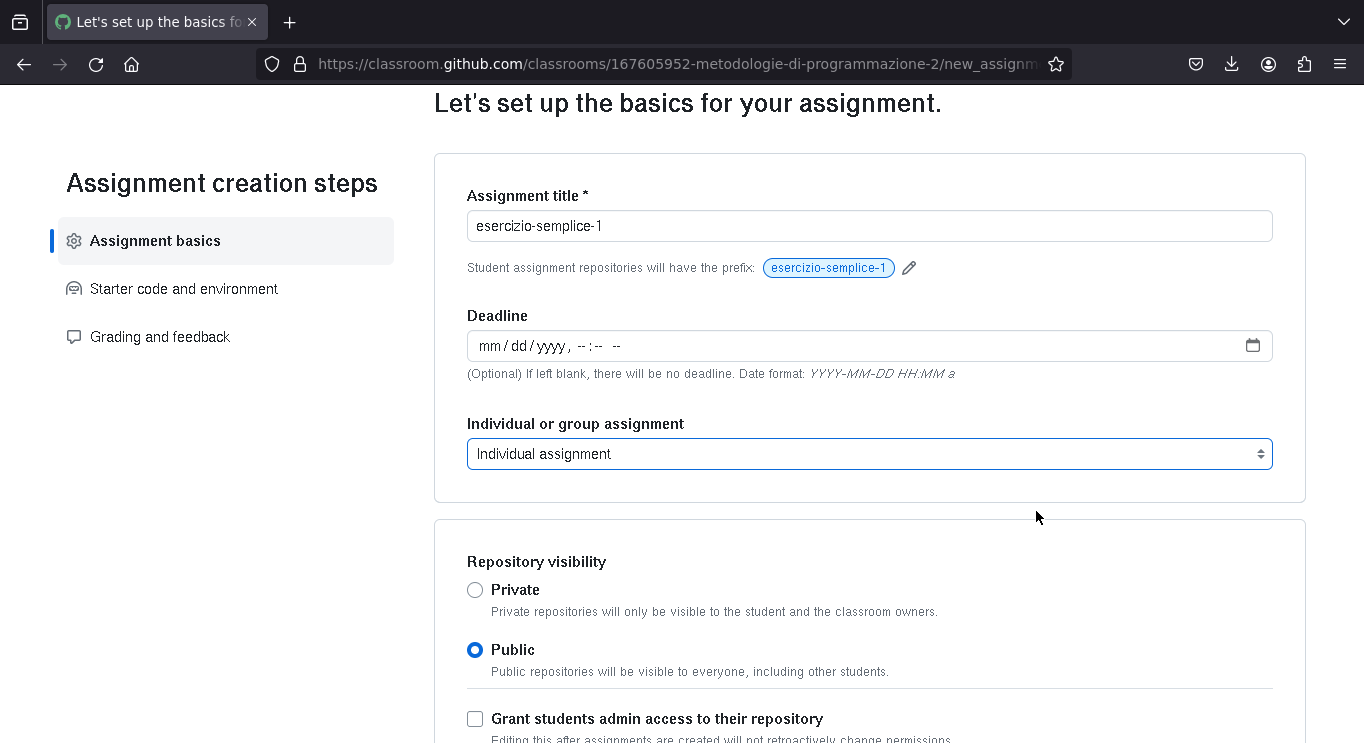
Assegnare esercizi
Una volta creata la "Classroom", questa è l'interfaccia di gestione dei degli esercizi
Individuale, di gruppo, pubblico o privato (scadenza opzionale)
Per assegnare un esercizio bisogna dare alcune informazioni di base: il nome, un'eventuale scadenza (opzionale), se si tratta di un esercizio di gruppo o individuale.
Quando lo studente "accetterà l'esercizio", verrà creato un repository (pubblico o privato) con il nome dell'esercizio e dello studente nell'organizzazione che avevamo scelto nella creazione della "Classroom"
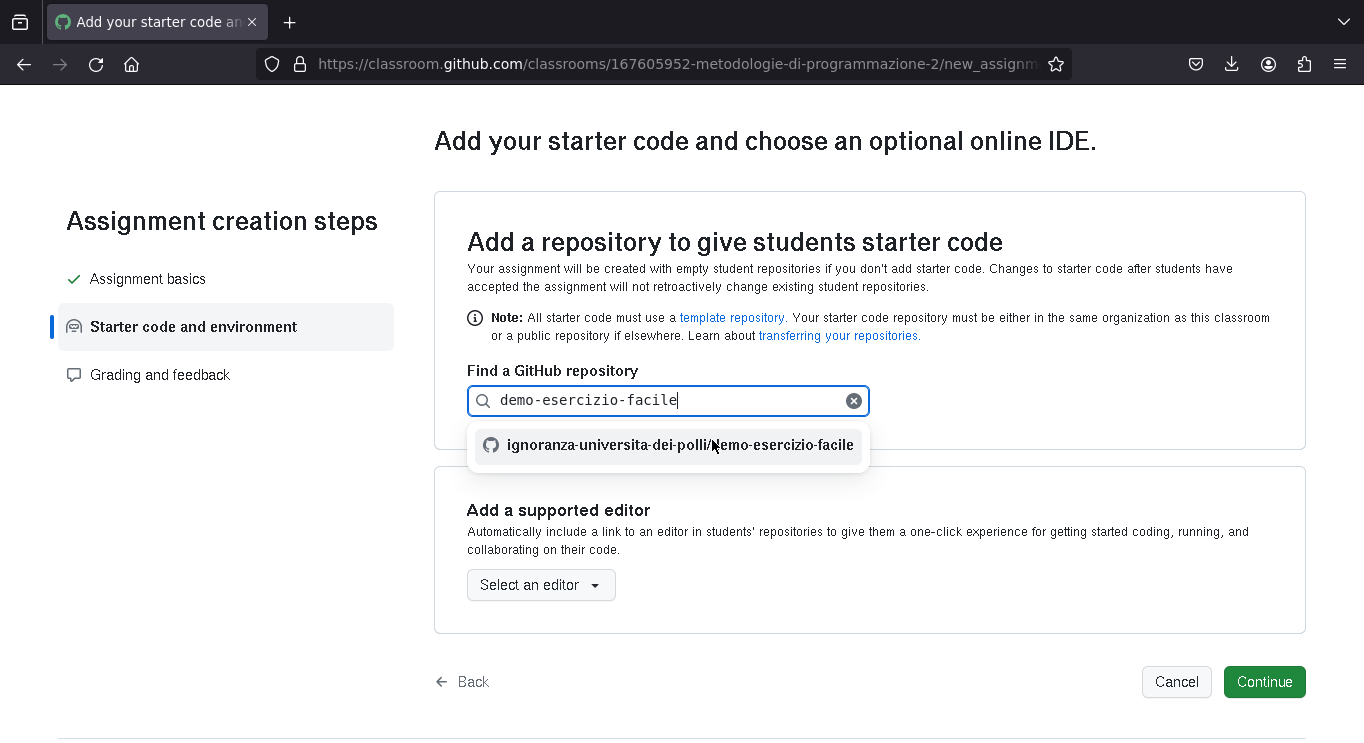
Successivamente, si sceglie il template (il repository con i test) da usare per l'esercizio (i template con i test vengono creati una volta, e si riusano ogni anno)
Template da usare per l'esrecizio
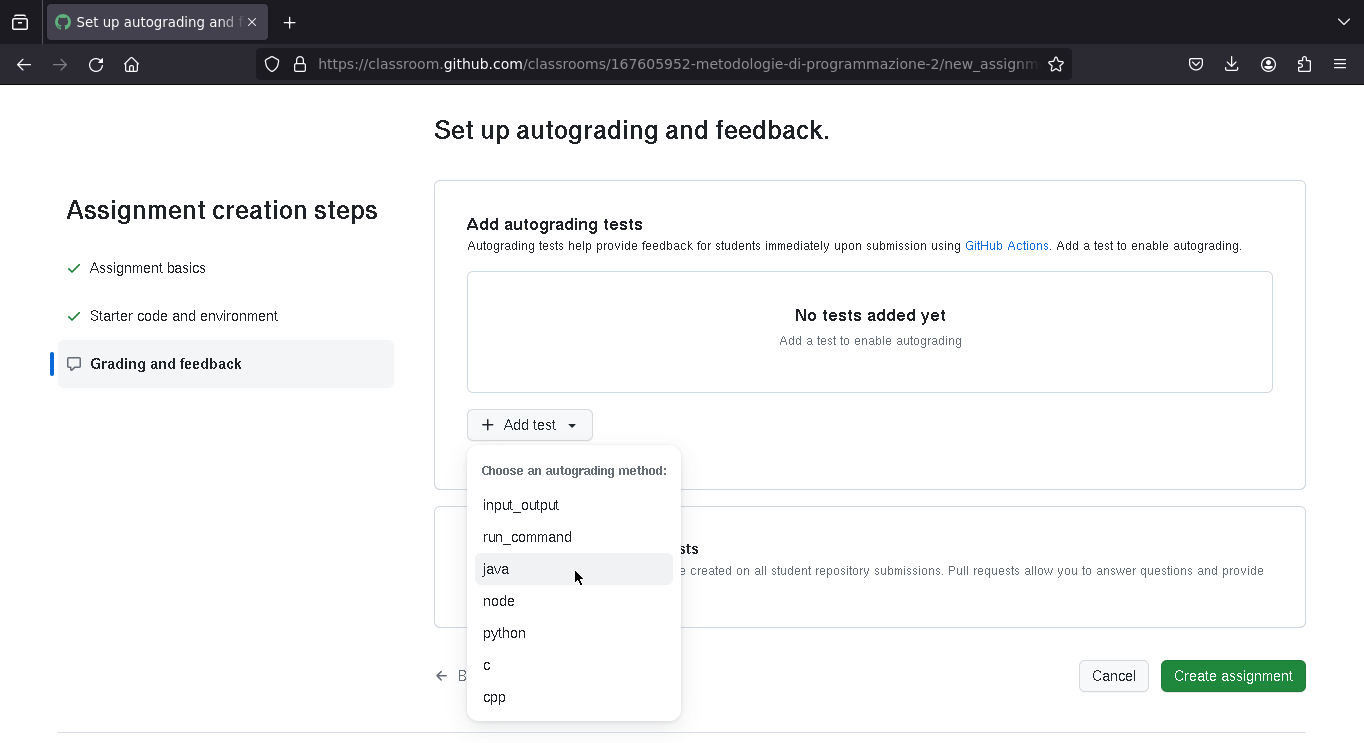
Test
Qui si può decidere di eseguire un comando unico che fa girare tutti i test (quindi l'esercizio può essere passato / non passato), oppure si può decidere di andare più a grana fine e far girare più comandi che eseguono ciascuno un sottoinsieme dei test.
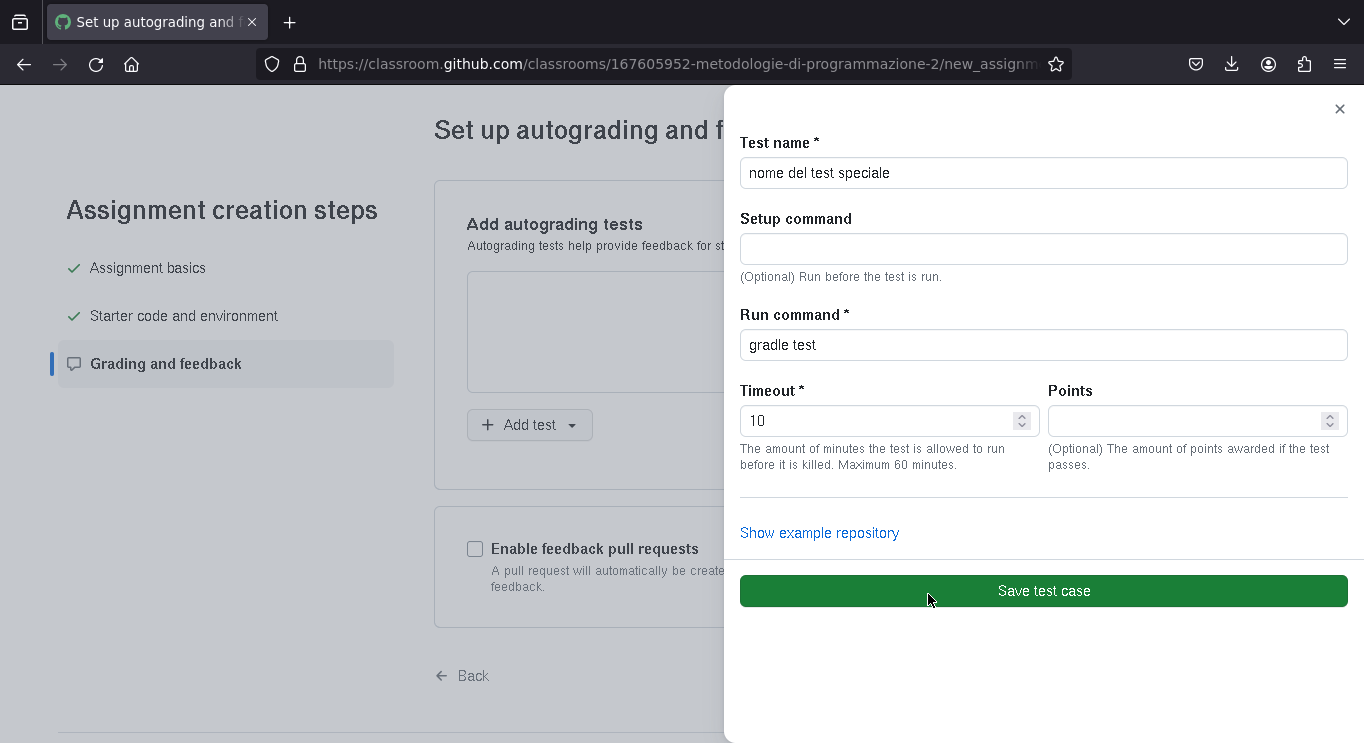
Riusare i test per gli anni futuri
Gli esercizi si possono riusare, quindi non è necessario ogni volta riscrivere i test per gli esercizi dell'anno passato. Si può prendere un esercizio dell'anno passato, cliccare il tasto "riusa" e si può riproporre lo stesso esercizio con gli stessi test in un anno successivo.
Condivisione esercizio
Una volta creato l'esercizio viene generato un link. Se gli studenti cliccano su quel link, possono accettare di fare l'esercizio, caso in cui viene creato un repository per il studente.
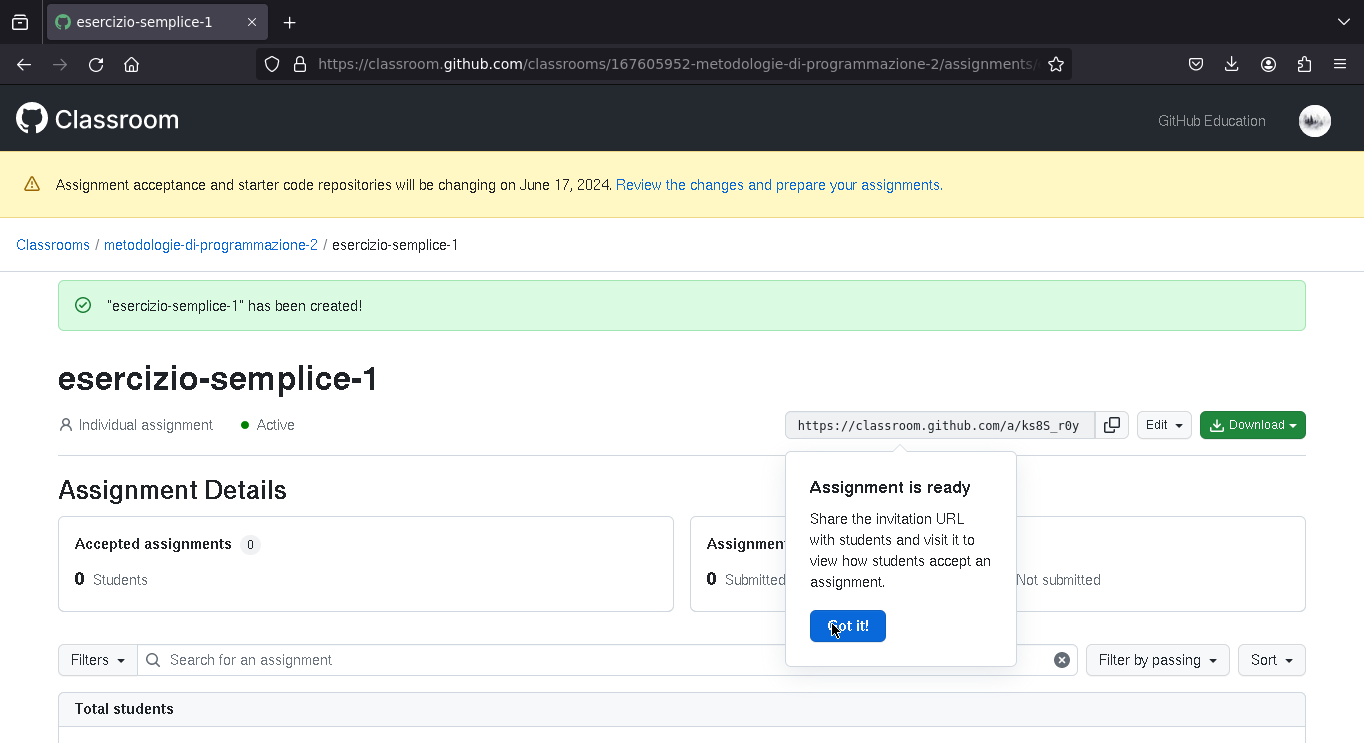
Svolgere gli esercizi
Accettare un homework
Questa è la schermata che vede uno studente quanto clicca un esercizio (se volete provare questo è il link di un esercizio https://classroom.github.com/a/lWBDk-we)
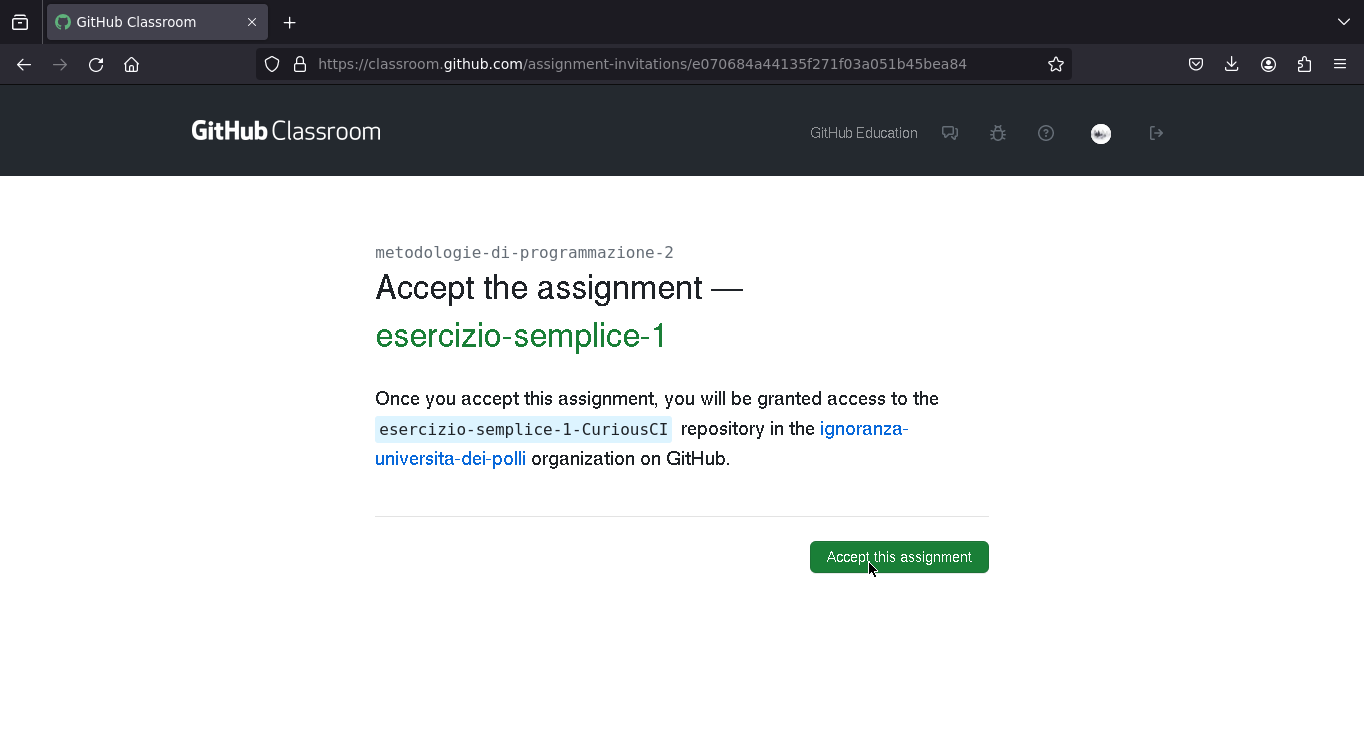
Link del repository appena creato
Testare in locale
Lo studente dovrà clonare il repository in locale (lo si può fare da CLI come preferisco io, altrimenti Eclipse ha integrate le funzionalità per lavorare con git e GitHub)
In questo esempio, per far girare i test ho eseguito il comando gradle test, per chi usa Eclipse, è già tutto integrato nell'editor, e possono eseguire i test cliccando sul tasto verder per eseguire il programma.
Qui un test fallisce.
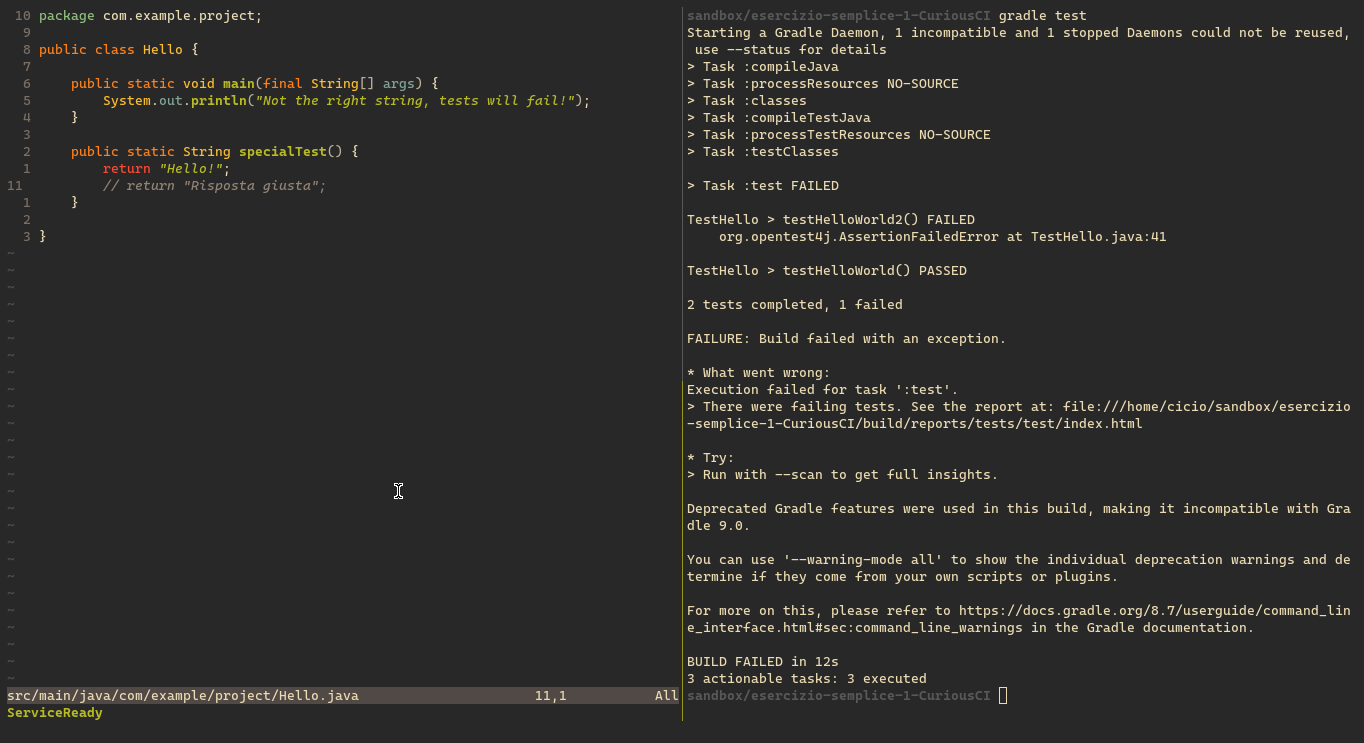
Lo studente scrive il codice per far funzionare il test. Ora i 2 test passano enrambi.
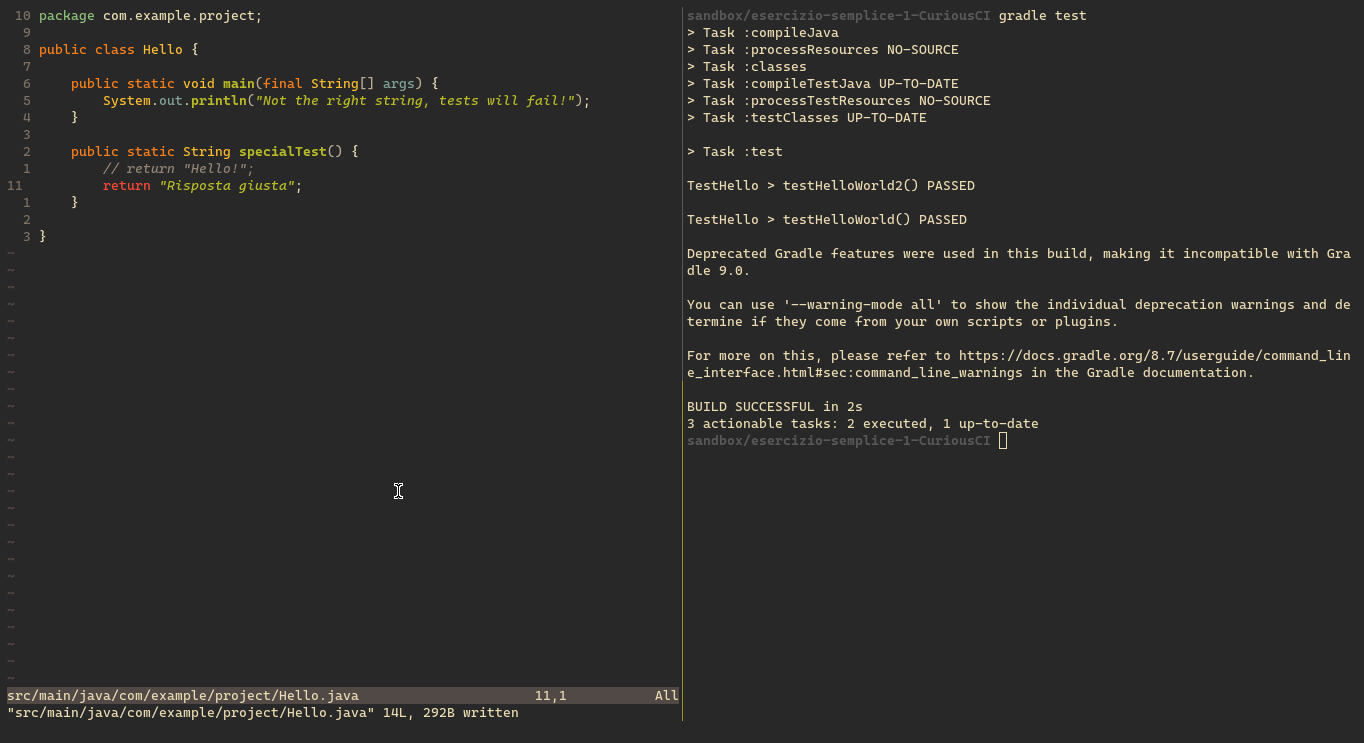
Pubblicare il codice
Una volta risolto l'esercizio (o anche parte di esso!) lo studente può fare il commit del codice al repository generato prima (usando git da CLI come nel mio caso, altrimenti Eclipse ha integrate le funzionalità per farlo in modo semplice)
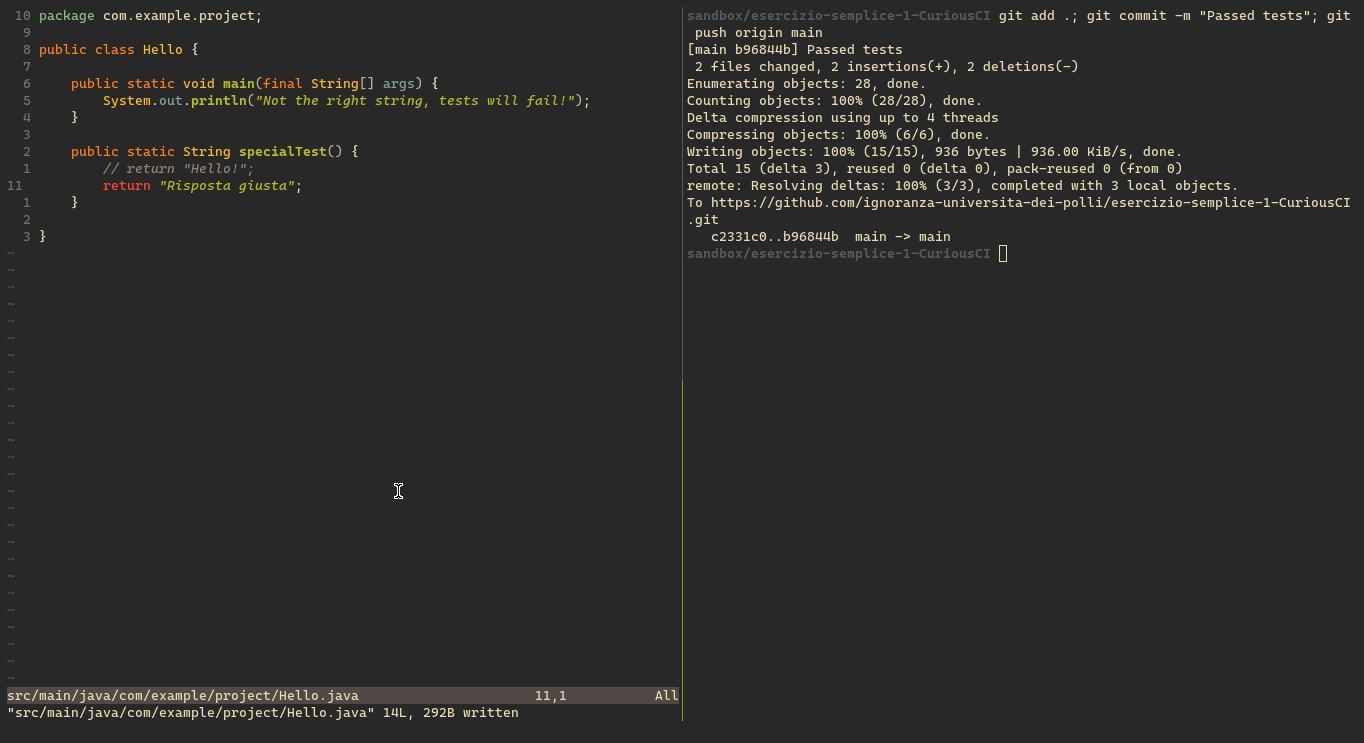
GitHub testa in automatico il codice
Quando lo studente fa il commit del codice, GitHub si occupa anche lui di esegure i test, per far vedere al docente quanti e quali test ha superato fino a quel momento lo studente.
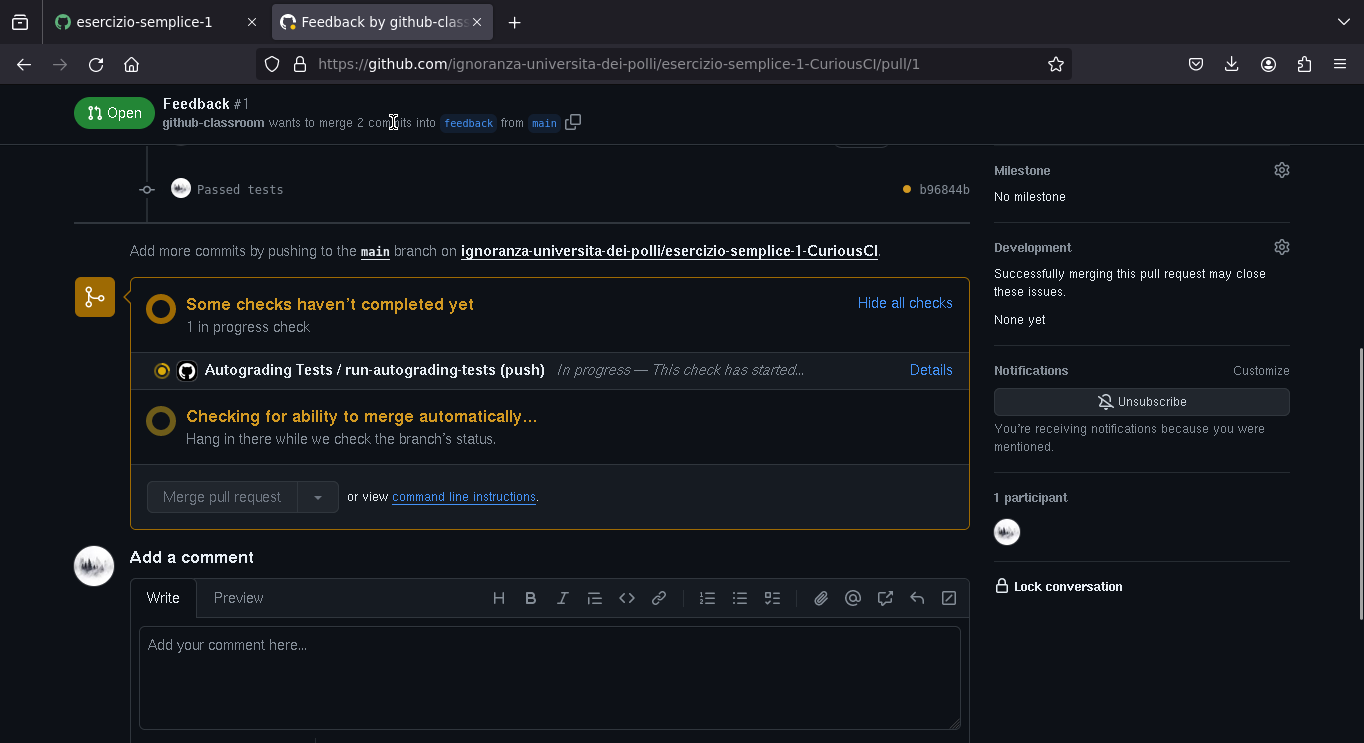
Esercizi dal punto di vista del doecente
Il docente può vedere l'elenco degli studenti che hanno accettato di fare l'esercizio, se hanno passato o meno i test, e possono andare a vedere il codice che hanno scritto (e lasciare un eventuale feedback manuale sul codice)
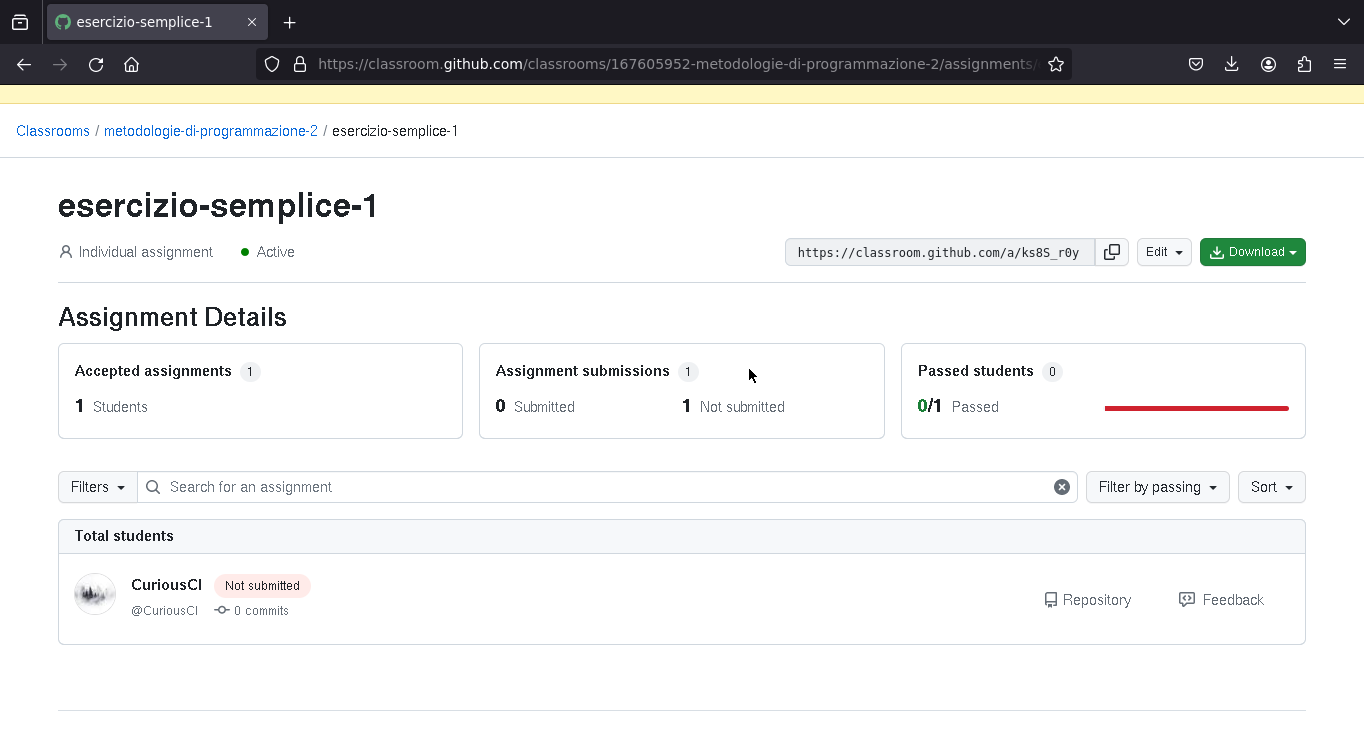
Feedback del docente
Eventualmente, il docente può vedere il codice che ha scritto lo studente.
Computer Architecture

1951 IAS Machine Architecture
This section is made to grasp a basic understand of how a computer architecture works, and it's not meant to be studied thoroughly.
The IAS Machine had a 1000 word memory, with a 40b word (40000b = 5000B ~ 5kB).
Word
Words are CA2 integers
| 0 | 000000000000000000000000000000000000000 |
|---|---|
| \(\pm 2^{39} \cdot bit\) | \(value\) |
Instruction words contain two instructions
| 00000000 | 000000000000 | 00000000 | 000000000000 |
|---|---|---|---|
| \(0..7\) | \(8..19\) | \(20..27\) | \(28..39\) |
| opcode | address | opcode | address |
CPU

| Name | Description | |
|---|---|---|
| MBR | Memory Buffer Register | receives & sends data to memory and I/O |
| MAR | Memory Address Register | current memory address |
| PC | Program Counter | address of the instruction to execute |
| IR | Instruction Register | contains instruction to execute |
| IBR | Instruction Buffer Register | contains the second instruction |
| AC | Accumulator | for partial calculation results |
| MQ | Multiplier Quotient | for partial calculation results |
Instructions
This isn't the full ISA of the IAS Machine, check it out here.
Transfer Instructions
| Description | |
|---|---|
| LOAD | AC \(\leftarrow\) AC operation Memory[Address] |
| LOAD | AC \(\leftarrow\) operation Memory[Address] |
| LDMQ | MQ \(\leftarrow\) Memory[Address] |
| ST | Memory[Address] \(\leftarrow\) AC |
| AMODL | Memory[Address][0..11] \(\leftarrow\) AC[0..11] (low) |
| AMODH | Memory[Address][20..31] \(\leftarrow\) AC[0..11] (high) |
Jumps
Like in modern assembly, jumps can be unconditional, conditional; for the IAS machine you had to specify either a low or high address.
| Description | |
|---|---|
| UBL | PC \(\leftarrow\) [Address] |
| UBH | PC \(\leftarrow\) [Address] + 1 |
| CBL | if AC \(\ge\) 0 { PC \(\leftarrow\) [Address] } |
| CBH | if AC \(\ge\) 0 { PC \(\leftarrow\) [Address] + 1 } |
Operations
| Description | |
|---|---|
| MUL | AC, MQ \(\leftarrow\) AC \(\cdot\) Memory[Address] |
| DIV | AC \(\leftarrow\) AC / Memory[Address] |
| DIV | MQ \(\leftarrow\) AC % Memory[Address] |
| LSHIFT | AC, MQ \(\leftarrow\) AC, MQ << X |
| RSHIFT | AC, MQ \(\leftarrow\) AC, MQ >> X |
| MOVE | AC \(\leftarrow\) AC operation MQ |
| IO | Transfer from and to I/O devices |
Example Program
LOAD 101
ADD 102
ST 103
How does it work?
- Fetch
- MAR \(\leftarrow\) PC
- IR, IBR \(\leftarrow\) MBR \(\leftarrow\) Memory[MAR]
- Decode
- MAR \(\leftarrow\) IR[8..19] ; address
- CU \(\leftarrow\) IR[0..8] ; opcode
- Exec
- AC \(\leftarrow\) MBR \(\leftarrow\) Memory[101]
- Decode
- MAR \(\leftarrow\) IBR[8..19] ; address
- CU \(\leftarrow\) IBR[0..8] ; opcode
- Exec
- AC \(\leftarrow\) AC + MBR \(\leftarrow\) Memory[102]
- PC
- PC \(\leftarrow\) PC + 1
- Fetch
- MAR \(\leftarrow\) PC
- IR, IBR \(\leftarrow\) MBR \(\leftarrow\) Memory[MAR]
- Decode
- MAR \(\leftarrow\) IR[8..19] ; address
- CU \(\leftarrow\) IR[0..8] ; opcode
- Exec
- Memory[103] \(\leftarrow\) MBR \(\leftarrow\) AC
MIPS
RISC vs CISC
Reduced Instruction Set Computer vs Complex Instruction Set Computer
| RISC | CISC |
|---|---|
| fixed size instructions | variable size instructions (requires decode before fetch) |
| fixed format | variable format (complex decode) |
| operations only with registers | in-memory operands |
| many registers | few of registers |
| single access to memory | multiple accesses to memory |
| fixed instruction duration | variable instruction duration |
| simple conflicts | complex conflicts |
| faster pipeline | complex pipeline |
Registers
| name | number | use | keep |
|---|---|---|---|
| at | 1 | reserved for assembler | ? |
| v1 | 2 - 3 | expression evaluation and results of functions | no |
| a3 | 4 - 7 | arguments | no |
| t7 | 8 - 15 | temporary | no |
| s7 | 16 - 23 | saved temporary | yes |
| t9 | 24 - 25 | temporary | no |
| k1 | 26 - 27 | reserved for OS Kernel | ? |
| sp | 29 | stack pointer | yes |
| ra | 31 | return address | yes |
Special registers
- sp points to the last location in use on the stack
- ra is written with the return address for a call by the jal instruction
Instructions
R-type Instructions
Arithmetic Instruction Format (type to a register)
add $t0, $s1, $s2
- add opcode \(\to\) 000000
- s1 in rs, \(\to\) 10001
- s2 in rt, \(\to\) 10010
- add funct \(\to\) 100000
| op | rs | rt | rd | shamt | funct |
|---|---|---|---|---|---|
| 000000 | 10001 | 10010 | 01000 | 00000 | 100000 |
| 6b | 5b | 5b | 5b | 5b | 6b |
| opcode | first register source | second register source | register destination operand | shift amount | function code |
I-type Instructions
Data Transfer Format (conditional jumps)
addi t2, <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8889em;vertical-align:-0.1944em;"></span><span class="mord mathnormal">s</span><span class="mord">2</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.1667em;"></span><span class="mord">4‘‘‘</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.6944em;"></span><span class="mord mathnormal">a</span><span class="mord mathnormal">dd</span><span class="mord mathnormal">i</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.8889em;vertical-align:-0.1944em;"></span><span class="mord">∗</span><span class="mord mathnormal">o</span><span class="mord mathnormal">p</span><span class="mord mathnormal">co</span><span class="mord mathnormal">d</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.4653em;"></span><span class="mord">∗</span></span><span class="mspace newline"></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mopen">(</span><span class="mrel">→</span></span><span class="mspace newline"></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mclose">)</span><span class="mord">001000</span><span class="mord">−</span></span></span></span>t2 in **rt** \\(\to\\) 01010
- s2 in **rs** \\(\to\\) 10010
| op | rs | rt | constant |
|:--:|:--:|:--:|:--:|
| 001000 | 10010 | 01010 | 0000000000000100 |
| 6b | 5b | 5b | 16b |
| opcode | first <br/> register | target <br/> register | constant value or <br/> address |
<!-- | \\(0..5\\) | \\(6..10\\) | \\(11..15\\) | \\(16..31\\) | -->
### J-type Instructions
Unconditional Jumps
```armasm
j label
- PC \(\leftarrow\) label \(\cdot\) 4
| op | address |
|---|---|
| 001000 | 10010010100000000000000100 |
| 6 bit | 26 bit |
FR-type Instructions
MIPS handles floating point instructions like regular 32b instructions. FR-type don't access the memory, and are executed by the FPU.
add.s f0, <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8889em;vertical-align:-0.1944em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord">1</span><span class="mpunct">,</span></span></span></span>f2 ; single precision
div.d <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8889em;vertical-align:-0.1944em;"></span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord">0</span><span class="mpunct">,</span></span></span></span>f2, f4 ; double precision
| op | rs | rt | rd | shamt | funct |
|---|---|---|---|---|---|
| 000000 | 10001 | 10010 | 01000 | 00000 | 100000 |
| 6b | 5b | 5b | 5b | 5b | 6b |
| opcode | first register source | second register source | register destination operand | shift amount | function code |
FI-type Instructions
FI-type are used for:
- load / store
- conditional jumps
lwc1 f1, indirizzo
bc1f cc, offset
| op | rs | rt | constant |
|---|---|---|---|
| 001000 | 10010 | 01010 | 0000000000000100 |
| 6b | 5b | 5b | 16b |
| opcode | first register | target register | constant value or address |
Interrupts
TODO: Interrupts
Assembly
Compilation
TODO: fill this section with instructions on how to compile assembly code
-
.s -> .o
-
.o -> .exe linking
-
windows
-
linux
Memory Layout of a Program

Directives
.globl
The .globl directive is useful when working with multiple files, and we need parts of code to reference labels in other files. If you don't use .globl, during the linking process, it can't find the label and gives an error.
We could have a main.asm file like this:
.globl main
.data
.text
main:
li $a0, 5
jal fibonacci
...
And a second file math.asm with the fibonacci function:
.globl fibonacci
.data
.text
fibonacci:
mv $t0, $a0
...
.ent
There is a .ent directive too, which is a debugger pseudo operation that marks the entry of main.
.globl main
.ent main
.text
main:
...
Pseudo-Instructions
Many instructions provided by MIPS, like move, lw etc... are decomposed into multiple instructions when the code is assembled; for more details. For example:
lw
lw $s0, value is mapped to:
lui $1, 0x00001001
lw $16, 0x00000000($1)
In the second case, 0x10010000 is the address of value, to get this address, we need to lui 0x00001001 (load upper immediate, loads the immediate value in the upper 16bits of the $1 register, which is the $at register). Then we can load into $16, which is the $s0 register, whatever value is at the address 0 + $at (0x00000000($1))
move
move $t0, $s0 is mapped to addu $8, $0, $16, where addu is the "add unsigned" operation, and $8 is $t0, $0 is the $zero constant register and $16 the $s0 register.
beq
ble $s1, $t0, label is mapped to:
slt $1, $8, $17
beq $1, $0, 0x00000001
Now, slt (set less than) sets the value in rs to 1 if rt is less than rd (if you don't know what rs, rt and rd are, check R-Type Instructions)
Absolute Jump
MIPS instructions have a fixed 32 bit size... what happens when you need to jump to an address which is a 32 bit constant? Neither I-type or J-type support 32 bit constants. We need to use lui and ori.
Let's suppose we have to jump at the address 0000_0000_1111_1111_0000_1001_0000_0000, which corresponds to 0x00ff0900.
lui $t0, 0x000000ff
ori $t0, 0x00000900
jr $t0
What lui does is moving the lower 16 bits 0x00ff into the upper part of register $t0, that way we have 0x00ff0000 in $t0. Now, we use ori (which does a bitwise or, basically compares with an or for each bit in $t0 with the value 0x00000900 for the lower half of the byte) so we have the full address. Now we can just use jr to jump to the address in the register.
Statements
For each statement, I'll show the C code (I chose C over other languages as the generated assembly is very minimal and easy to understand), and the relative MIPS implementation; under details I'll leave the x_86 assembly generated by cl.exe on Windows and gcc on Linux.
Conditions
If-Else
int main() {
int x = 0;
if (x > 0)
x += 5;
else
x += 10;
}
.text
li $t0, 0 #; x = 0
blez $t0, else #; if x <= 0, goto else
if:
addi $t0, $t0, 5 #; add 5 to x if x > 0
j end #; don't execute else part
else:
addi $t0, $s1, 10 #; add 10 to x if x <= 0
end:
Switch
int main() {
int x = 1;
switch (x) {
case 0:
x += 16;
break;
case 1:
x += 16 * 2;
break;
case 2:
x += 16 * 3;
break;
}
}
.data
dest: .word case0, case1, case2
.text
#; sll $t0, $t0, 2 #; choose the case
li $t0, 0 #; first case
addi $t0, $t0, 4 #; jump one case
#; addi $t0, $t0, 8 #; jump two cases
lw $t1, dest($t0) #; load case address to $t1
jr $t1 #; Jump to the case address in $t1 (case0, case1 etc...)
li $t2, 0
case0:
addi $t2, $zero, 0x10
j break
case1:
addi $t2, $zero, 0x20
j break
case2:
addi $t2, $zero, 0x30
j break
break:
Iterations
Do-While
int main() {
int x = 0, i = 0;
do {
x += 4;
i += 1;
} while (i < 10);
}
.text
li $t0, 0 #; x = 0
li $t1, 0 #; i = 0
do:
addi $t0, $t0, 4 #; x += 4
addi $t1, $t1, 1 #; i += 1
blt $t1, 10, do #; if i < 10, repeat the cicle
While
int main() {
int x = 0, i = 0;
while (i < 10) {
x += 4;
i += 1;
}
}
.text
li $t0, 0 #; x = 0
li $t1, 0 #; i = 0
while:
bge $t1, 10, end #; if i >= 10, end the while loop
addi $t0, $t0, 4 #; x += 4
addi $t1, $t1, 1 #; i += 1
j while #; repeat cicle
end:
For
int main() {
int x = 0;
for (int i = 0; i <= 10; i++)
x += i;
}
.text
li $t0, 0 #; x = 0
li $t1, 0 #; i = 0
for:
beq $t1, 10, end #; if i == 10, end loop
add $t0, $t0, $t1 #; x += i
addi $t1, $t1, 1 #; i += 1
j for
end:
Vectors & Matrices
Endianness
The MIPS architecture allows both big-endian and little-endian byte ordering, but the little-endian one is most commonly used. Endianness has to do on how bytes are addressed in memory, and it's related to how the access of each individual byte is made.
ASCII
TODO ASCII
Vectors
There are many types of vectors you can handle in MIPS:
.data
byte: .byte 29, 8, 1, 29, 2, -3
half: .half 10, -4, 20, -8, 22, 12
word: .word 2, 29012, 29, 5, -12905, -290125
# decimal
float: .float 2.5, -1.2, 21.90, -5.0
double: .double 2.5, -1.2, 21.90, -5.0
# strings
string: .asciiz "Holy Moly, who ate my Canoli?"
Note that .asciiz stands for "zero terminated string", which means it has a '\0' nullchar at the end.
Vector Iterations
You can iterate vectors and matrices in two ways:
Index
- useful if you need the index of each element
- the increment of the index doesn't depend on the size of the elements
- you have to convert the index each time, according to the size of the elements
.data
vector: .word 10, 2, 980, 29, 1992, -2, 59, 280, 99
size: .word 9
.text
la $s0, vector #; s0 = vector address
la $t1, size #; t1 = address of size
lw $t1, ($t1) #; t1 = size
li $t0, 0 #; t0 is the index i
for:
bge $t0, $t1, end #; if i == size, end loop
sll $t2, $t0, 2 #; offset = i * 4 (shift logic left by 2)
addi $t2, $t2, $s0 #; t2 = current address = offset + address
lw $t7, ($t2) #; load value from current address, and maybe use it
#; rest of the code ...
addi $t0, $t0, 1 #; i = i + 1
j for #; loop again
end:
TODO: check if it works
Pointer
- you work directly with the address
- less calculations to do in the cycle
- you don't have the index of the element
- the increment depends on the size of the elements
- you must calculate the index after the last element
.data
vector: .word 10, 2, 980, 29, 1992, -2, 59, 280, 99
size: .word 9
.text
la $t0, vector #; t0 = vector address
la $t1, size #; t1 = address of size
lw $t1, ($t1) #; t1 = size
sll $t1, $t1, 2 #; size = size * 4 (we are handling words)
add $t1, $t0, $t1 #; t1 = end address = vector address + size * 4 (this is the address after the last one in the vector)
for:
bge $t0, $t1, end #; if current address == vector end address, end loop
lw $t7, ($t0) #; load value from current address, and maybe use it
#; rest of the code ...
addi $t0, $t0, 4 #; current address = current address + 4 (we move by 4 bytes, because we are using words)
j for #; loop again
end:
TODO: check if it works
Matrices
If you want a 7 (rows) x 13 (columns) matrix, you need enough space for 91 elements:
.data
matrix: .word 0:91
Matrixes are stored in memory like vectors, each row is laid one after the other. To work with n-sized matrices, you just lay out one matrix after the other in memory (you can have a 3-dimensional matrix, for example, where the z coordinate dictates the layer, or the matrix, you are working with)
Syscalls & Procedures
Syscalls
Syscalls are a powerful tool, which enables interaction with I/O, files, and dynamic allocation of memory. The MARS editor supports 59 different syscalls. Here's a few of useful ones.
To use syscalls, there are some special registers:
$v0is used for the code of the syscall$a0to$a3are used for parameters- The output is usually saved in
$v0
By setting these registers to the desired values, and using the syscall instruction, the OS will run the operation.
| service | a0 = integer to print | | | print string | 4 | v0 contains integer read | | | read string | 8 | a1 = maximum number of characters to read | | | sbrk (allocate heap memory) | 9 | v0 contains address of allocated memory | | print character | 11 | v0 contains character read | | exit | 10 | | | | exit2 | 17 | a0 = result | |
Files
| service | v0 | arguments | output |
|---|---|---|---|
| open file | 13 | a1 = flags v0 contains file descriptor (negative if error) | |
| read from file | 14 | a1 = address of input buffer v0 contains number of characters read (0 if end-of-file, negative if error) | |
| write to file | 15 | a1 = address of output buffer v0 contains number of characters written (negative if error) | |
| close file | 16 | a0 = file descriptor |
Hello World!
.globl main
.data
string: .asciiz "Hello World!"
.text
main:
li v0, 4
la a0, string
syscall
Procedures
Procedures are pieces of code that take parameters, and return a result. They're useful to make the code cleaner and more modular.
.globl main
.text
main:
li a0, 5 #; first parameter
li a1, 6 #; second parameter
jal function #; call function
return:
li v0, 17
li a0, 0
syscall #; we have to exit, or the execution will continue
function:
subi sp, sp, 12 #; we need 4 bytes * 3 registers
sw ra, 8(sp) #; return address
sw a0, 4(<span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mclose">)</span><span class="mord mathnormal">s</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span></span></span></span>a1, 0(sp)
#; function body...
#; I can use jal, because we have saved in memory ra
lw <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">a</span><span class="mord">1</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.1667em;"></span><span class="mopen">(</span></span></span></span>sp)
lw <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">a</span><span class="mord">0</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.1667em;"></span><span class="mord">4</span><span class="mopen">(</span></span></span></span>sp)
lw <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mpunct">,</span><span class="mspace" style="margin-right:0.1667em;"></span><span class="mord">8</span><span class="mopen">(</span></span></span></span>sp)
addi <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.625em;vertical-align:-0.1944em;"></span><span class="mord mathnormal">s</span><span class="mord mathnormal">p</span><span class="mpunct">,</span></span></span></span>sp, 12 #; reset stack pointer
jr <span class="katex"><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8889em;vertical-align:-0.1944em;"></span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">a</span><span class="mord">‘‘‘</span><span class="mord mathnormal" style="margin-right:0.13889em;">T</span><span class="mord mathnormal">h</span><span class="mord mathnormal">e</span><span class="mord mathnormal">b</span><span class="mord mathnormal" style="margin-right:0.01968em;">l</span><span class="mord mathnormal">oc</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">e</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">u</span><span class="mord mathnormal">n</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal" style="margin-right:0.03148em;">ak</span><span class="mord mathnormal">es</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">ro</span><span class="mord mathnormal">m</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.6944em;"></span><span class="mord">∗</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.6944em;"></span><span class="mord">∗</span><span class="mord mathnormal">i</span><span class="mord mathnormal">sc</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.01968em;">ll</span><span class="mord mathnormal">e</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.8889em;vertical-align:-0.1944em;"></span><span class="mord">∗</span><span class="mord mathnormal">s</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">am</span><span class="mord mathnormal">e</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.4653em;"></span><span class="mord">∗</span><span class="mord mathnormal" style="margin-right:0.02778em;">or</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.6944em;"></span><span class="mord">∗</span><span class="mord mathnormal">a</span><span class="mord mathnormal">c</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.03588em;">v</span><span class="mord mathnormal">a</span><span class="mord mathnormal">t</span><span class="mord mathnormal">i</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal" style="margin-right:0.02778em;">recor</span><span class="mord mathnormal">d</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">∗</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:0.6944em;"></span><span class="mord">∗</span><span class="mord">.</span><span class="mord mathnormal" style="margin-right:0.13889em;">W</span><span class="mord mathnormal">ec</span><span class="mord mathnormal">an</span><span class="mord mathnormal">u</span><span class="mord mathnormal">se</span><span class="mord">‘</span></span></span></span>fp` to point to the start of the **activation record**, it's rendundant and rarely used.
## Recursions
Functions calling themselves!
> TODO: complete factorial
```armasm
.globl main
.text
main:
li $a0, 5
jal factorial
print:
move $a0, $v0 #; integer = result of factorial function
li $v0, 1 #; print integer
syscall
return:
li $v0, 17
li $a0, 0
syscall
factorial:
#; jump by 1
#; recursive step
#; base case
returnFactorial:
lw $ra, ($sp)
addi $sp, $sp
jr $ra
Exercises
These are the implementations of the exercises presentend in course's slides and notations.
; pdf 3 slide 10
.data
.text
li $s0, 2 #; a = 2
li $s1, 5 #; b = 5
li $s2, 9 #; c = 9
li $s3, 4 #; d = 4
li $s4, 12 #; e = 12
#; a = ( b - c ) + ( d - e )
sub $t0, $s1, $s2 #; t0 = b - c
sub $t1, $s3, $s4 #; t1 = d - e
add $s0, $t0, $t1 #; s0 = t0 + t1
; pdf 3 slide 11
.data
variable: 10
vector: .word 12, 4, 59, 9, 19, 8, 6, 18, 9, 19, 28, 12, 100
.text
la $s6, variable #; s6 = address of variable
la $s5, vector #; s5 = address of vector
#; vector[12] = vector[6] + variable
lw $t0, ($s6) #; t0 = *s6 (value at address s6, which is the value of the variable)
lw $t1, 24($s5) #; t1 = s5[6] ; s5[6] = *(s5 + 6), but 6 rappresents words, not bytes, so 6 * 4 = 24 (which corresponds to vector[6])
add $t0, $t0, $t1 #; t0 += t1 (which is vector[5])
sw $t0, 48($s5) #; stores result of sum (from t0) to vector[12], but 12 is words, so 48 is bytes
; pdf 3 slide 17
.data
.text
li $s0, 1 #; u = 1
li $s1, 0 #; v = 0
#; v = u * 256
sll $s1, $s0, 8 #; s1 = s0 * 256
#; which is the first value that breaks?
#; a word ha 32 bits, multiplying by 256 means shifting by 8 bits
#; this means that as soon as we have the 25 bit set to 1, the 1 is shifted out of 32
#; 2^24 = 16777216
li $s2, 16777216 #; 16777215 will work normally
sll $s0, $s2, 8 #; becomes 0
; pdf 4 slide 34
.data
vector: .word 11, 35, 2, 7, 29, 95
size: .word 6
.text
#; find max value in vector
la $t0, vector #; t0 = current address
la $t1, vector #; t1 = end of vector
la $t2, size #; t2 = address of vector size
lw $t2, ($t2) #; t2 = vector size
sll, $t2, $t2, 2 #; t2 *= 4, to accomodate words
add $t1, $t1, $t2 #; t1 = end of vector + vector size
lw $t2, ($t0) #; t2 = max value
for:
bgt $t0, $t1, endFor #; if current address > end of vector, end for
lw $t3, ($t0) #; load value from current address
ble $t3, $t2, elseSmaller #; if current value <= max value, continue
ifBigger:
move $t2, $t3 #; max value = current value
elseSmaller:
addi $t0, $t0, 4 #; current address = next address
j for #; repeat cycle
endFor:
; pdf 4 slide 35
.data
vector: .word 4, -1, 5, 500, 0, 10000, -256
size: .word 5
sums: .word 0, 0
.text
#; find max value in vector
la $t0, vector #; t0 = current address
la $t1, vector #; t1 = end of vector
la $t2, size #; t2 = address of vector size
lw $t2, ($t2) #; t2 = vector size
sll, $t2, $t2, 2 #; t2 *= 4, to accomodate words
add $t1, $t1, $t2 #; t1 = end of vector + vector size
li $t2, 0 #; t2 = parity
li $t4, 0 #; t4 = even
li $t5, 0 #; t5 = odd
for:
bgt $t0, $t1, endFor #; if current address > end of vector, end for
lw $t3, ($t0) #; load value from current address
beq $t2, 1, ifIsOdd #; check if current parity is odd
ifIsEven:
add $t4, $t4, $t3 #; even += current value
li $t2, 1 #; parity = odd
j nextIteration
ifIsOdd:
add $t5, $t5, $t3 #; odd += current value
li $t2, 0 #; parity = even
nextIteration:
addi $t0, $t0, 4 #; current address = next address
j for #; repeat cycle
endFor:
la $t6, sums #; t6 = address of the result
sw $t4, ($t6) #; t6[0] = even
sw $t5, 4($t6) #; t6[1] = odd; 4 is used instead of 1 because a word is 4 bytes long
; pdf 5 slide 10
.data
vector: .byte 1, 2, 3, 4
.text
#; the vector corresponds to the word 0x04030201
#; which basically is 4, 3, 2, 1
#; as it's rappresented in memory using little-endian
; pdf 6 slide 7
.globl main
.data
matrix: .word 2, -10, -10, -10, 2, -10, -10, -10, 2
length: .word 3
.text
main:
la $t0, matrix #; t0: matrix_address = matrix
la $t1, length #; t1: matrix_length_address = length
lw $t1, ($t1) #; t1: matrix_length = *length
move $t2, $t1 #; t2: jumps_to_do = matrix_length (to count how many jumps are needed to reach the end)
addi $t1, $t1, 1 #; t1: jump_length = matrix_length += 1 (to jump to next diagonal cell)
sll $t1, $t1, 2 #; t1: jump_length = jump_length * 4 (because words are 4 bytes long)
li $t3, 0 #; t3: sum = 0
while:
beq $t2, 0, end #; if jumps_to_do == 0 { end loop }
lw $t4, ($t0) #; t4: value = *matrix_address
add $t3, $t3, $t4 #; sum += value
subi $t2, $t2, 1 #; jumps_to_do -= 1
add $t0, $t0, $t1 #; matrix_address = matrix_address = jump_length
j while
end:
print:
li $v0, 1 #; print integer
move $a0, $t3 #; integer = sum
syscall
return:
li $v0, 17 #; exit
li $a0, 0 #; result = 0
syscall
; pdf 7 slide 22
.globl main
.data
.text
main:
li $a0, 5
li $a1, -3
li $a2, 9
li $a3, 2
jal avgOfSquareAbsSub
print:
move $a0, $v0 #; integer = formula
li $v0, 1 #; print integer
syscall
return:
li $v0, 17 #; exit
li $a0, 0 #; result = 0
syscall
avgOfSquareAbsSub:
subi $sp, $sp, 8 #; ra, first result
sw $ra, ($sp)
jal squareAbsSub #; x, y
sw $v0, 4($sp) #; t0: first = (|x|-|y|)^2
move $a0, $a2
move $a1, $a3
jal squareAbsSub #; w, z
move $t1, $v0 #; t1: second = (|w|-|z|)^2
lw $t0, 4($sp) #; t0: first = (|x|-|y|)^2
add $t0, $t0, $t1 #; first += second
srl $v0, $t0, 1 #; numerator /= 2
returnAvg:
lw $ra, ($sp)
addi $sp, $sp, 8
jr $ra
squareAbsSub:
subi $sp, $sp, 4 #; ra
sw $ra, ($sp)
jal abs #; |x|
move $t0, $v0 #; t0: abs_x = |x|
move $a0, $a1 #; number = y
jal abs #; |y|
move $t1, $v0 #; t1: abs_y = |y|
sub $t0, $t0, $t1 #; difference = |x| - |y|
mul $v0, $t0, $t0 #; result = (|x| - |y|)^2
returnSub:
lw $ra, ($sp)
addi $sp, $sp, 4
jr $ra
abs:
bge $a0, 0, returnAbs #; if number >= 0, return
ca2:
nor $a0, $a0, $zero #; number = bitwise not of number
addi $a0, $a0, 1 #; number += 1
returnAbs:
move $v0, $a0 #; result = |number|
jr $ra
Single Clock Cycle Architecture

ALU Control
R-type instructions have 6 bits in the funct field to control the ALU. The first two bits are the ALUOp to indicate 1 of 3 selection codes. Based on the selection code, the next 4 bits could have a different meaning.
| opcode | ALUOp | funct field | operation | ALUControl |
|---|---|---|---|---|
| lw / sw | 00 | don't care always a sum | sum | 0010 |
| beq | 01 | don't care always a subtraction | sub | 0110 |
| R-type | 10 | 10_0000 | ALUControl decides based on last 4 bits | 0010 |
Based on the instruction type, we have different behaviours for the funct field and the ALUControl.
| # | func | function |
|---|---|---|
| 0 | 0000 | AND |
| 1 | 0001 | OR |
| 2 | 0010 | add |
| 6 | 0110 | subtract |
| 7 | 0111 | slt |
| 12 | 1100 | NOR |
Control Unit Signals
| signal | on false | on true |
|---|---|---|
| RegDst | write register number comes from rt | write register number comes from rd |
| RegWrite | the data is written in in the write register | |
| ALUSrc | data comes from register 2 | data comes from sign extender (immediate part) |
| PCSrc | next instruction is PC + 4 | next instruction is PC + 4 + immediate |
| MemRead | read from memory and put in read data value at address | |
| MemWrite | data at address calculated from ALU, is overwritten by data in register 2 | |
| MemToReg | data to write in register file comes from ALU | data to write in register file comes from memory |
Exercise
Based on the following instructions, write the truth table for the Control Unit, having as input 6 bits (opcode) and as output 9 bits (control signals)
| op | opcode | RegDst | ALUSrc | MemtoReg | RegWrite | MemRead | MemWrite | Branch | ALUOp |
|---|---|---|---|---|---|---|---|---|---|
| R | 000000 | 1 | 0 | 0 | 1 | X | 0 | 0 | 10 |
| lw | 100011 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 00 |
| sw | 101011 | 0 | 1 | 0 | 0 | X | 1 | 0 | 00 |
| beq | 000100 | 0 | 0 | X | 0 | X | 0 | 1 | 01 |
Note: the exercise is correct, but there are some places in which we can use don't cares instead of actual values. From here, we can create a PLA with the necessary functions.
Adding New Instructions
j
Let's try to add a j (jump) instruction to the current archtecture.
We must define:
- it's encoding
- it's behaviour
- the functional units we need
- the flux of information
- necessary control signals
- execution time (and wether it impacts the total time)
| opcode | immediate value |
|---|---|
| 000010 | 11011101001001001001100111 |
| \(31-26\) | \(25-0\) |
The immediate value is the absolute address to which we have to jump to (divided by 4). To get the full address we have to expand the immediate value:
| PC + 4 first 4 bits | immediate value | multiplication by 4 |
|---|---|---|
| 0110 | 11011101001001001001100111 | 00 |
We have to shift the immediate value by 2, because the instructions are 4 bytes long, so we have to multiply by 4 the absolute address. Then, we get the missing 4 bits from PC + 4, so we stay within the same 256Mb block (the first 4 bits identify the block, so the size of the block is \(2^{28} bit = 2^8 bit * 2^{20} \approx 2^8 * 10^6 \approx 256 Mb \)).
\(PC \leftarrow (PC + 4)[31..28] \ or \ (instruction[25..0] << 2)\)
We also need a jump control signal, to determine wether we are jumping or not, and we have to make sure that we don't write any registers or memory. In pink, the implementation of the j instruction.

jal
The jal (jump and link) instruction is a J-type that does the same thing as j, with the difference that it saves in $ra (register number 31) the current value of the PC + 4.
\( $ra \leftarrow PC + 4 \)

jr
It's an I-type instruction, we just have to link whatever value we read from rs and move it into PC.

addi
Not all instructions require modifications to the circuitery, like addi.
Exercise
Add to the CPU the R-type instruction
jrr rs(jump relative to register) , which jumps to the address (relative to the PC) contained inrs. \(PC \leftarrow PC + 4 + reg[rs]\)

Control Signals
| op | Jrr | Jump | RegDst | ALUSrc | MemtoReg | RegWrite | MemRead | MemWrite | Branch | ALUOp |
|---|---|---|---|---|---|---|---|---|---|---|
| jrr | 1 | 0 | X | X | X | 0 | X | 0 | X | XX |
TODO: execution time and clock
Pipeline
We can divide the execution of an instruction into phases:
- Fetch: load instruction from memory
- Instruction decode: CU decodes instruction into signals, and values are read from registers
- Execution: the ALU does the operation, or the access to memory or the branch
- Memory Access: memory is read or written (
lw,sw) - Write Back: the result of the ALU operation, or the Memory operation is put in the write register
In each moment in time, in a single clock cycle architecture, 80% of the CPU isn't working (only one operation is executed at a time). With a pipeline we can solve this problem by doing an instruction step by step, so in each phase there's a different instruction.
Register File and Clock
The read and write of the register file happen during the same clock cycle. It's basically a latch that writes (the previous instruction) when the clock is 1, and reads the values in the register is 0.

Pipelined Architecture

Pipelined Architecture with Branches

We can group the control signals we've used up until now based on the section they're used in: EXE, MEM, WB.
| opcode | ALUSrc | RegDest | ALUOp1 | ALUOp2 | Branch | MemRead | MemWrite | MemToReg | RegWrite |
|---|---|---|---|---|---|---|---|---|---|
| R-Type | 0 | 1 | 1 | 0 | 0 | X | 0 | 0 | 1 |
| lw | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| sw | 1 | X | 0 | 0 | 0 | X | 1 | X | 0 |
| beq | 0 | X | 0 | 1 | 1 | X | 0 | X | 0 |
Hazard
There are various hazards that can present on a pipelined architecture, which don't happen on a single clock cycle architecture, because we are executing multiple instructions at the same time, without waiting for the previous ones to finish.
There are three types of hazards:
- Structural Hazards: hardware resources aren't enough (if the instruction memory and data memory are the same, there could be collision in the instruction fetch phase, and mem phase); these are solved during design.
- Data Hazards: if the required data isn't ready yet.
- Control Hazards: a jump changes the flow of the instructions' execution.
Let's look at an example:
add $s0, $t0, $t1
sub $t2, $s0, $t3
Let's see what happens if we use a pipeline!
| add | IF | ID | EX | ME | WB | |
| sub | IF | ID | EX | ME | WB |
The above alignment doesn't work, because during the ID of the sub instruction, we read an old value of $s0, which hasn't been updated with the WB.
| add | IF | ID | EX | ME | WB | ||
| sub | \(\rightarrow\) | IF | ID | EX | ME | WB |
The same happens here: while the add instruction is still waiting for the memory access, we try to read the value $s0, which still hasn't been updated with the WB phase.
| add | IF | ID | EX | ME | WB | |||
| sub | \(\rightarrow\) | \(\rightarrow\) | IF | ID | EX | ME | WB |
This is a valid configuration! As we can see here, the WB phase happens before the ID phase, during the same clock cycle, so we can run these phases of the two instructions at the same time.
Bypassing/Forwarding
In some cases, like this one, the required value could be in the pipeline before the WB phase: in the example above, the new value in $s0 is available right after the EX phase, after the ALU does the operation, and we don't have to wait for a MEM phase. In this case, we can build a shortcut between the result of the ALU, and one of the parameters of the ALU in the next clock cycle. To do this, we have to first detect when we actually need this behaviour.
With such a shortcut, we don't need to wait for the WB.
| add | IF | ID | EX | ME | WB | |
| sub | IF | ID | EX | ME | WB |
Bubble
In some cases, shortcuts can't be used, so we have to wait one or two instructions before continuing with the next instructions. To wait 1 cycle, we add a bubble, which is an empty instruction, a nop (all 0 values, doesn't affect the registers and memory; it's a valid instruction)
Instruction Rearrangement
Sometimes, by rearranging the instructions, we can solve some of these hazards. Let's look at an example.
lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
lw $t4, 8($t0)
add $t5, $t1, $t4
sw $t5, 16($t0)
TODO: complete example
Data Hazards & Forwarding Unit
EXE

#![allow(unused)] fn main() { if EX/MM.RegWrite == 1 && EX/MM.MemRead == 0 { ID/EX.rs == EX/MM.rd || ID/EX.rt == EX/MM.rd } if MM/WB.RegWrite == 1 && MM/WB.MemRead == 0 { ID/EX.rs == MM/WB.rd || ID/EX.rt == MM/WB.rd } }
MemRead has to be 0, because when MemRead is 1, it's an I-Type instruction, and the rd value doesn't have the wanted meaning (could be detected as an hazard, when it's clearly not). RegWrite has to be 1, or this means the instruction before doesn't modify the data.
Then it's just a metter of checking if one register (rs or rt) of the current instruction ID/EX matches with the destination register of the previous one, or the previous two.
Now we have to determine the precedence of the data hazards in EXE.
#![allow(unused)] fn main() { if MM/WB.RegWrite == 1 && !(EX/MM.RegWrite == 1) && EX/MM.rd != ID/EX.rt && MM/WB.rd == ID/EX.rt { forwardB = 01 } }
If the value in MM/WB (instruction 2) is valid and needed, and I'm not forwarding the value in EX/MM (instruction 1), then I can forward instruction 2.
Here's a table describing the behaviour of the Forwarding Unit, which handles the forwarding.
| control | source |
|---|---|
| forwardA = 00 | ID/EX (current) |
| forwardA = 01 | EX/MM (previous) |
| forwardA = 10 | MM/WB (before previous) |
| forwardB = 00 | ID/EX (current) |
| forwardB = 01 | EX/MM (previous) |
| forwardB = 10 | MM/WB (before previous) |

MEM
It happens only in one case:
lw $t0, offset($t1)
sw $t0, offset($t2)
To detect it it's simple enough: you just have to determine if the previous instruction has MemRead and RegWrite set to 1, and the current one has MemWrite set to 1, and in both the instructions the address of rt is the same.
ID
Required only if beq is calculated in ID.
Control Hazard
beq $t0, $t1, else
lw $s1, ($s1)
else:
ori $s1, $s1, 10
In this case, we might need to discard the lw instruction which was loaded before jumping to the ori instruction.To make sure the program executes correctly, we can insert two nop instructions, that way, while we run the branch instruction, and we wait for the EXE to calculate the jump, we load 2 empty instruction which don't change the state of the CPU (these are called "bubbles").
beq $t0, $t1, else
nop
nop
lw $s1, ($s1)
else:
ori $s1, $s1, 10
If we can predict the jump in the ID phase, we need just 1 nop. It doesn't always work like this, as in some loops, we actually jump just at the end. In that case, the jump is never executed, and we can load the next instruction instead of a nop:
.data
array: .word 1, 5, 8, 7, 6
size: .word 5
.text
xor $t1, $t1, $t1 #; i = 0
sub $s1, $s1, $s1 #; s = 0
lw $s7, size #; load size into register
sll $s7, $s7, 2 #; multiply $s7 by 4 (due to word size)
while:
bge $t1, $s7, whileEnd #; if i >= size { jump to end }
lw $t2, array($t1) # load array[i]; bge is true only once!
add $s0, $s0, $t2 # s += array[i]
addi $t1, $t1, 4 #; i += 1
j while
whileEnd:
That's why the CPU tries to predict the branch, and tries to load the next instruction or the nop depending on which is executed most often.
We can move the jump decision in ID instead of EXE; in this case:
- we have to put just 1
nopafter (inEXEwe need 2) - if we have a
lwbefore, we need 2nopbefore (instead of 1) - if we have a R-Type data hazard, we need 1
nopbefore (instead of none)
Anticipating jump
The j instruction has OPCode 000010, this means that once we fetch the instruction from memory, we can already jump to the address, just by comparing the OPCode.
Branch Prediction
We can count with a hardware solution how many jumps have been done to decide wether it's more likely the jump will be taken or not. To predict a jump, we need a simple FSM with 4 states, which changes prediction after 2 fasle positives (this way, inside loops with a prevalent choice, we always do the most efficient one).

Exercise
TOOD Full Pipelined architecture
Cache
A cache is divided into blocks
| line # | valid | tag | block |
|---|---|---|---|
| multiple blocks can have the same line | to determine wether the data is valid | distinguishes a block from the others | the block of data itself |
| 0 | 0 | 101 | 01001001_11010010 |
| 1 | 1 | 011 | 11001011_01001100 |
| 2 | 1 | 111 | 11010010_11001011 |
| 3 | 0 | 000 | 01001100_00100110 |
| 4 | 1 | 010 | 00100110_00100110 |
Direct Mapping
The following is an exmple of a cache with 4 words, with 2 lines
| # | word | byte1 | byte2 | byte3 | byte4 |
|---|---|---|---|---|---|
| 0 | 0 | 00000000 | 00000000 | 00000000 | 00000000 |
| 0 | 1 | 00000000 | 00000000 | 00000000 | 00000000 |
| 0 | 2 | 00000000 | 00000000 | 00000000 | 00000000 |
| 0 | 3 | 00000000 | 00000000 | 00000000 | 00000000 |
| 1 | 0 | 00000000 | 00000000 | 00000000 | 00000000 |
| 1 | 1 | 00000000 | 00000000 | 00000000 | 00000000 |
| 1 | 2 | 00000000 | 00000000 | 00000000 | 00000000 |
| 1 | 3 | 00000000 | 00000000 | 00000000 | 00000000 |
Now let's see how to determine where to get a word in the cache, based on its value (with 4 word blocks, in a 2 line cache).
| tag | line # | word | byte |
|---|---|---|---|
| 000000000000000000001000000 | 0 | 10 | 01 |
To determine a HIT in a cache it's easy (where multiple words are present in a block, there's the need for a mux to determine which word to get data from)

Cache Size
To determine the size of a direct mapping cache we need some data:
- \(2^n\) lines
- \(2^m\) words block size
- 1 validity bit
tag size = \(32 - n - m - 2\)
cache size in bits = \(2^n \cdot (2^m + 1 + tag\_size) \)
Associativity
By making the cache more associative, we reduce the number of conflict misses.
Cache Size pt. 2
TODO: pdf 22, slide 11
Policies
Replacement Policy
- LRU (least recently used), it requires a bit to determine how old a block is, to decide which one to replace (the oldest one)
- LFU (least frequently used), replace the least frequently used, but it requires a more complex hardware (it requires a counter for each set, the counter is updated at every access)
- RANDOM, replace a random block
Writing Policy
It's the policy used to update the RAM when the cache is written.
- Write through, at each update, the block is updated in RAM (good for consistency on multi-core systems, very slow)
- Write back, the blocks is updated only when replaced, (faster, but the content in the cache isn't in sync with the content in RAM)
By using a DIRTY bit, we can manage to save in RAM only blocks which have been changed.
MISS types
- Cold start, when the address is requested for the first time (solved by making bigger blocks)
- Conflict, when the block has been replaced due to the associativity of the cache (solved by increasing the associativity)
- Capacity, the block has been replaced due to the size of the cache (solved by increasing the size of the cache)
Cache & Parallelism
In multi-processor architectures there are multiple parallel caches, which have fast communication to keep the data coherent. Multiple difference processes can access and modify the same data.
There must be a way to keep consistency and coherence of the data in multiple caches.
To solve this problem, there are two strategies:
- distributed protocol which caches use to communicate
- centralized manager which handles the interactions
Cache Controller FSA
Finite State Automaton
stateDiagram-v2
IDLE --> Tag
Tag --> IDLE
Allocation --> Tag
Tag --> Allocation
Tag --> WriteBack
WriteBack --> WriteBack
WriteBack --> Allocation
Allocation --> Allocation
The writes of different processors must be read in order.
Cache Invalidation Protocol
Coherence is when the value I read is the last one written, consistency means that all data is consistent (calendar - message example)
Virtual Memory
In a multi process system, it's hard to manage the memory for all the processes; there could be a problem with memory not being sufficient for all the processes. The solution is to make the addresses of the processes "virtual", and map them to physical ones when needed.
The memory is divided in pages, which are stored on a slower memory when not needed.
Each process has a page table which takes a virtual page and maps it to a physical page.
| valid | dirty | used | physical page address |
|---|---|---|---|
| 1 | 0 | 0 | address in mass memory |
| 1 | 1 | 0 | address in mass memory |
| 0 | 0 | 0 | address in mass memory |
| 1 | 1 | 1 | address in mass memory |
When valid is 1, the page is in RAM, but you still need 2 accesses to get the address. When valid is 0, the page is in a mass storage, a page fault exception is launched, and it requires millions of clock cycles to get the data from memory.
Policies
Replacement Policy
- LRU
- LFU
- RANDOM
Writing Policy
- Write back (because write through requires too much time)
TLB
A Translation Lookaside Buffer is a special buffer used to access virtual memory addresses faster.
Algorithms & Data Structures I
Implementations and exercises for Algo I 2022/2023 course at Sapienza Universita' di Roma (Computer Science Bachelor's degree) in Rust 🦀, cos it's more fun!
Table of contents
The content in the checked boxes was summarized / implemented / completed. If you need explanations on some content, just open an issue, and I'll be happy to help 😄.
(Completed in Rust 56 out of 149 ~ 38%)
- Introduction
- Big O notation
- Cost
-
Searching Algorithms
- Linear Search
- Binary Search (iterative)
- Ex 1 (TODO: test again)
- Recursion
- Let's just not... pt.1
- Let's just not... pt.2
- Naive Sorting
- Merge Sort
- Quick Sort
- Heap Sort
- Linear Sorting
- Linked List
- Queue & Stack
- Linked List exercises
-
Tree
- Graph Theory
- TreeNode (Tree built with Records)
- Positional Binary Tree (Basically a Heap)
- ParentTree (Tree built with Two Arrays)
- Operations
- Ex 1
- Ex 2
- DFS/BFS
- Dictionary
- Binary Search Tree
- Black-Red Tree
- Exercises pt.1
- Exercises pt.2
- Exercises pt.3
-
Other
- Tim Sort
- Has Duplicates in Merge Sort
- Merge Sort on Linked List (iterative)
- Python List (TODO: look info about it's implementation)
- [Pytohn Utils](https://twiki.di.uniroma1.it/pub/Intro_algo/AD/Dispense/METODI_UTILI_IN_PYTHON.pdf
Computational Cost
Sums
Recurrence Equations
We'll analyzer the computational cost of the following recursive search algorithm.
def search(list, value, index=0):
if list[index] == value:
return index;
if index == len(list) - 1:
return None
return search(list, value, index + 1)
The first step, requires writing out a system of the equation and the base case of the algorithm.
Now let's solve the equation, in four different methods.
Iterative
Idea: - develop the equation and express it as sum of terms depending on and the base case.
Difficulty: - many algebric calculations to do.
Then we calculate the equation when , the base case.
Tree
TODO: draw trees in markdown!
Substitution
Idea: - ipothize a solution for the given recurrence equation - verify (by induction) wether it works
Difficulty: - it's hard to find a solution as close as possible to the real solution - it's used mainly in demonstrations
Let's suppose , and , where and are fixed constants.
This doesn't mean that T(1), which is a is the same as , so we need two constants.
Now we have to prove that is a and a using induction.
where k is to be determined.
Base Case
First, check for which values the base case is verified.
Induction
Then check if the general case is covered by the base case.
We get that , we can always find constants and so that greater than both, so the induction is verified.
where k is to be determined.
Base Case
First, check for which values the base case is verified.
Induction
Then check if the general case is covered by the base case.
We get that , we can always find constants and so that smaller than both, so the induction is verified.
Main
Idea: - It's a set of formulas to solve a recurrence equation
Difficulty: - works only when the equation is in the form with
Theorem
Given
The equation:
There are three cases that can generate by comparing with :
The comparison must be polynomial, by an order of .
Where not to apply it?
In the following examples, the main method cannot be applied.
Ex 1
In this case, is asintotically bigger than n, but not plynomially bigger. In fact
Ex 2
In this case, is asintotically smaller than n, but not plynomially smaller. In fact
Searching Algorithms
A bunch of searching algorithms on arrays 🔎.
Linear Search
Rust
#![allow(unused)] fn main() { pub fn linear_search<T: Eq>(array: &[T], value: T) -> Option<usize> { array .iter() .enumerate() .find_map(|(i, v)| if *v == value { Some(i) } else { None }) } }
Java
public static <T> Optional<Integer> search(T[] array, T toFind) {
for (var index = 0; index < array.length; index++)
if (array[index] == toFind)
return Optional.of(index);
return Optional.empty();
}
Binary Search
In the course, you will study the recursive implementation of the binary search, in my code, I've written an iterative one (I don't "like" recurion)
Rust
#![allow(unused)] fn main() { pub fn binary_search<T: Ord>(array: &[T], value: T) -> Option<usize> { let mut step = array.len(); let mut index = 0; while step > 0 { let next = index + step; while next < array.len() { let cmp = match array.get(next) { Some(v) => v.cmp(&value), None => break, }; match cmp { Equal => return Some(next), Less => index = next, Greater => break, } } step /= 2; } None } }
Java
public static <T extends Comparable<? super T>> Optional<Integer> binarySearch(T[] array, T toFind) {
int jump = array.length - 1, index = 0;
while (jump > 0) {
while (index + jump < array.length) {
var comparison = array[index + jump].compareTo(toFind);
if (comparison > 0)
break;
index += jump;
if (comparison == 0)
return Optional.of(index);
}
jump /= 2;
}
return Optional.empty();
}
Exercise
Given , an
array of integers, and two values and , with , count how many elements of are included in the range
The simplest way to solve the problem is to implement two functions: lower_bound and upper_bound, which are basically binary searches that don't stop once they find the value in the array. In the case of lower_bound, it finds the index of "the smallest value bigger or equal to ", and the upper_bound is "the biggest value smaller or equal to " with being the value to find.
This way, we can find the upper_bound of , and the lower_bound of , and do a subtraction of the two to find the number of elements inbetween. There are a few corner cases to consider both for upper_bound, lower_bound and count_in_range (the function that solves the exercise) for which we return 0 (open an ISSUE if you want me to discuss them).
Rust
#![allow(unused)] fn main() { pub fn upper_bound<T: Ord>(array: &Vec<T>, value: T) -> Option<usize> { let mut step = array.len(); let mut index = 0; if array.first().unwrap() > &value { return None; } while step > 0 { let next = index + step; while next < array.len() { let cmp = match array.get(next) { Some(v) => v.cmp(&value), None => break, }; match cmp { Greater => break, _ => index = next, } } step /= 2; } Some(index) } }
#![allow(unused)] fn main() { pub fn lower_bound<T: Ord>(vector: &Vec<T>, value: T) -> Option<usize> { let mut step = vector.len(); let mut index = vector.len() - 1; if vector.last().unwrap() < &value { return None; } while step > 0 { while step <= index { let cmp = match vector.get(index - step) { Some(v) => v.cmp(&value), None => break, }; match cmp { Less => break, _ => index -= step, } } step /= 2; } Some(index) } }
#![allow(unused)] fn main() { pub fn count_in_range<T: Ord>(vector: Vec<T>, lower: T, upper: T) -> usize { let lower = lower_bound(&vector, lower); let upper = upper_bound(&vector, upper); if let (Some(l), Some(u)) = (lower, upper) { return match l.cmp(&u) { Greater => 0, _ => u.abs_diff(l) + 1, }; } 0 } }
Java
TODO: make bound functions return Optional, handle corner cases
public static <T extends Comparable<? super T>> Integer upperBound(List<T> list, T toFind) {
int jump = list.size() - 1, index = 0;
while (jump > 0) {
while (index + jump < list.size() && list.get(index + jump).compareTo(toFind) <= 0)
index += jump;
jump /= 2;
}
return index;
}
public static <T extends Comparable<? super T>> Integer lowerBound(List<T> list, T toFind) {
int jump = list.size() - 1, index = list.size() - 1;
while (jump > 0) {
while (index - jump >= 0 && list.get(index - jump).compareTo(toFind) >= 0)
index -= jump;
jump /= 2;
}
return index;
}
TODO: write a countInRange method
Recursion
These are just a bunch of recursive functions and exercises, nothing too special. There should be a faster way to write a recursive fibonacci with doubling, I'll work on it.
#![allow(unused)] fn main() { pub fn linear_search<T: Eq>(array: &[T], value: T, index: usize) -> Option<usize> { if index == array.len() { return None; } if let Some(v) = array.get(index) { if *v == value { return Some(index); } } linear_search(array, value, index + 1) } pub fn binary_search<T: Ord>(array: &[T], value: T, start: usize, end: usize) -> Option<usize> { if start == end { return None; } let mid = (end - start) / 2; if let Some(v) = array.get(mid) { match value.cmp(v) { Equal => Some(mid), Greater => binary_search(array, value, mid + 1, end), _ => binary_search(array, value, start, mid), }; } None } pub fn factorial(number: usize) -> usize { if number == 0 { return 1; } number * factorial(number - 1) } pub fn fibonacci(nth: usize) -> usize { if nth == 0 || nth == 1 { return 1; } fibonacci(nth - 1) + fibonacci(nth - 2) } }
TODO: fast fibonacci
Guided Exercises
#![allow(unused)] fn main() { // Ex 1, kth power of n pub fn pow(base: usize, exponent: usize) -> usize { if exponent == 0 { return 1; } base * pow(base, exponent - 1) } // Ex 2, sum of elements pub fn sum(array: &[usize], index: usize) -> usize { if let Some(x) = array.get(index) { return x + sum(array, index + 1); } 0 } // Ex 3, find min pub fn min<T: Ord>(array: &[T], index: usize) -> Option<&T> { if index == array.len() { return None; } std::cmp::min(array.get(index), min(array, index + 1)) } // Ex 4, palindrome pub fn is_palindrome<T: Eq>(_array: &[T], _index: usize) -> bool { false } // Ex 5, reverse print pub fn reverse_print<T: Debug>(array: &[T], index: usize) { if let Some(t) = array.get(index) { print!("{:?}", t); reverse_print(array, index - 1) } } // Ex 6, print in order pub fn print<T: Debug>(array: &[T], index: usize) { if let Some(t) = array.get(index) { print!("{:?}", t); print(array, index + 1) } } // Ex 7, hanoi }
TODO: Hanoi
Exercises
TODO: Binomial
#![allow(unused)] fn main() { // Ex 1, binomial // Ex 2, GCD pub fn gcd(x: usize, y: usize) -> usize { if y == 0 { return x; } gcd(y, x % y) } }
Naive Sorting
Insertion Sort
Rust
#![allow(unused)] fn main() { pub fn insertion_sort<T: Ord>(array: &mut [T]) { for i in 1..array.len() { for j in (1..=i).rev() { if array[j - 1] < array[j] { break; } array.swap(j - 1, j); } } } }
Java
static <T extends Comparable<? super T>> void insertionSort(List<T> list, Integer start, Integer end) {
for (var index = start + 1; index < end; index++) {
var left = index;
while (left > start && list.get(left).compareTo(list.get(left - 1)) < 0) {
// swap
var temp = list.get(left);
list.set(left, list.get(left - 1));
list.set(left - 1, temp);
left--;
}
}
}
Selection Sort
Rust
#![allow(unused)] fn main() { pub fn selection_sort<T: Ord>(vector: &mut [T]) { for i in 0..vector.len() - 1 { let (j, _) = (&vector[i..]) .iter() .enumerate() .min_by(|&(_, x), &(_, y)| x.cmp(y)) .unwrap(); vector.swap(i, j + i); } } }
Java
public static <T extends Comparable<? super T>> void selectionSort(List<T> list) {
for (int index = 0; index < list.size(); index++) {
var minIndex = min(list, index);
var temp = list.get(index);
list.set(index, list.get(minIndex));
list.set(minIndex, temp);
}
}
Bubble Sort
Rust
#![allow(unused)] fn main() { pub fn bubble_sort<T: Ord>(vector: &mut [T]) { for i in 0..vector.len() { for j in (i + 1..vector.len()).rev() { if vector[j] < vector[j - 1] { vector.swap(j, j - 1) } } } } }
Java
public static <T extends Comparable<? super T>> void bubbleSort(List<T> list) {
for (var left = 0; left < list.size(); left++)
for (var right = left; right < list.size(); right++)
if (list.get(left).compareTo(list.get(right)) > 0) {
var temp = list.get(left);
list.set(left, list.get(right));
list.set(right, temp);
}
}
Exercises
Just a bunch of exercises related to sorting.
Rust
#![allow(unused)] fn main() { // Pdf 8, Slide 35 pub mod exercises { use std::ops::Range; // Ex 1, pt. 1 pub fn reversed_bubble_sort<T: Ord>(vector: &mut [T]) { for i in (0..vector.len() - 1).rev() { for j in 0..=i { if vector[j] < vector[j + 1] { vector.swap(j, j + 1) } } } } // Ex 1, pt. 2, Which are stable? // Insertion Sort - stable // Selection Sort - stable // Bubble Sort - unstable // Ex 1, pt. 3, Cost if sorted? Cost if all equal? // Insertion Sort - sorted O(n) - equal O(n) // Selection Sort - sorted O(n^2) - equal O(n^2) // Bubble Sort - sorted O(n^2) - equal O(n^2) // Ex 2, pt. 1, Write an insertion_sort using a separate function for min pub fn min_in_range<T: Ord>(vector: &[T], r: Range<usize>) -> usize { let (index, _) = (&vector[r]) .iter() .enumerate() .min_by(|&(_, x), &(_, y)| x.cmp(y)) .unwrap(); index } pub fn min_selection_sort<T: Ord>(vector: &mut [T]) { for i in 0..vector.len() - 1 { let j = min_in_range(vector, i..vector.len()); vector.swap(i, i + j); } } // Ex 2, pt. 2, Check if array has_duplicates, based on naive sorting algorithms pub fn has_duplicates<T: Eq>(vector: &[T]) -> bool { for (index, value) in vector.iter().enumerate() { if (vector[index + 1..]).iter().filter(|&x| x == value).count() > 0 { return true; } } false } } }
Merge Sort
Quick Sort
Heap Sort
Heap
To code a heap_sort function, we need to implement the heap data structure on an array.
#![allow(unused)] fn main() { pub struct Heap<T> { buffer: Box<[T]>, size: usize, } }
Looks simple enough... now we need a way to create a heap (ideally from a boxed slice) or just create an empty one in which to insert values later.
#![allow(unused)] fn main() { impl<T: Copy + Ord> From<Box<[T]>> for Heap<T> { fn from(value: Box<[T]>) -> Self { let mut heap = Self { size: value.len(), buffer: value, }; heap.build(); heap } } }
We'll look into the specification of the Heap::build method later, to see what does it do, and why it requires Copy and Ord traits.
#![allow(unused)] fn main() { impl<T: Default + Copy> Heap<T> { pub fn new<const SIZE: usize>() -> Self { Self { buffer: Box::new([Default::default(); SIZE]), size: 0, } } } }
Heap Methods
heapify is the most important method to make a heap work: it basically rearranges in \(O(\log{n})\) a Heap in which only the root is out of order.
#![allow(unused)] fn main() { impl<T: Ord + Copy> Heap<T> { fn heapify(&mut self, node: usize) { use std::cmp::max; if let Some((v, i)) = max(self.child(node, 1), self.child(node, 2)) { if self.buffer.get(node) < v { self.buffer.swap(node, i); self.heapify(i) } } } } }
Now that we have the heapify method, to build the Heap, we just need to run heapify on the left side of the array.
#![allow(unused)] fn main() { impl<T: Ord + Copy> Heap<T> { fn build(&mut self) { (0..self.size / 2).rev().for_each(|n| self.heapify(n)); } } }
Indexing a Heap
In a Heap, to get the children of a node at an index i, we just need a formula:
i * 2 + 1for the left childi * 2 + 2for the right child
Knowing this, we can write a child method to get the children of a node in a Heap, and reuse it in the heapify method.
#![allow(unused)] fn main() { impl<T: Ord + Copy> Heap<T> { fn child(&self, node: usize, child: usize) -> Option<(Option<&T>, usize)> { let node = 2 * node + child; if node >= self.size { return None; } Some((self.buffer.get(node), node)) } } }
Iterating a Heap
Now that we have the Heap setup, we just need to implement the Iterator trait to consume the Heap. The next method is very simple: we just swap the last element with the root (in position 0), reduce the size of the Heap, and run heapify again.
#![allow(unused)] fn main() { impl<T: Ord + Copy> Iterator for Heap<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { if self.size == 0 { return None; } self.buffer.swap(0, self.size - 1); self.size -= 1; self.heapify(0); Some(self.buffer[self.size]) } } }
Heap Sort
Now sorting a Heap becomes a very easy task! We just have to run heapify until the there are no more elements, and the unerlying buffer will be sorted.
#![allow(unused)] fn main() { pub fn heap_sort<T: Ord + Copy + Default>(buffer: Box<[T]>) { Heap::from(buffer).into_iter().for_each(drop); } }
Exercises
#![allow(unused)] fn main() { pub mod exercises { use std::cmp::Reverse; use super::*; // Ex 1, O(n) for MaxHeap, O(1) for MinHeap pub enum BinaryHeap<T> { MaxHeap(Heap<T>), MinHeap(MinHeap<T>), } pub fn min<T: Ord + Copy + Default>(heap: &mut BinaryHeap<T>) -> Option<T> { match heap { BinaryHeap::MaxHeap(heap) => heap.last(), BinaryHeap::MinHeap(heap) => heap.next(), } } // Ex 2, Build a MinHeap struct pub struct MinHeap<T> { heap: Heap<T>, } impl<T: Ord + Default + Copy> MinHeap<Reverse<T>> { pub fn from(buffer: Box<[T]>) -> Self { Self { heap: Heap::from( buffer .iter() .map(|v| Reverse(*v)) .collect::<Vec<Reverse<T>>>() .into_boxed_slice(), ), } } } impl<T: Ord + Default + Copy> Iterator for MinHeap<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { self.heap.next() } } // Ex 3, insert in Heap with available space impl<T: Ord + Default + Copy> Heap<T> { pub fn insert(&mut self, value: T) -> Result<(), &'static str> { if self.size >= self.buffer.len() { return Err("Array is full"); } self.buffer[self.size] = value; self.size += 1; self.build(); Ok(()) } } } }
\(O(n)\) Sorting Algorithms
Counting Sort
#![allow(unused)] fn main() { pub fn counting_sort<'a>(array: &'a mut [usize]) { let mut counter: Vec<usize> = vec![0; *array.iter().max().unwrap_or(&mut 0) + 1]; for n in array.iter() { counter[*n] += 1; } let mut index = 0; for (number, &count) in counter.iter().enumerate() { for _ in 0..count { array[index] = number; index += 1; } } } }
Stable Counting Sort
It works on generics too!
#![allow(unused)] fn main() { pub trait IntoIndex { fn into_index(&self) -> usize; } pub fn stable_counting_sort<'a, T: Clone + Copy + IntoIndex + Default>(array: &'a mut [T]) { let mut counter: Vec<usize> = vec![0; array.iter().map(T::into_index).max().unwrap_or(0) + 1]; for n in array.iter().map(T::into_index) { counter[n] += 1; } let mut positions = counter; for i in 1..positions.len() { positions[i] += positions[i - 1]; } let mut tmp: Vec<T> = vec![T::default(); array.len()]; for k in array.iter().rev() { tmp[positions[k.into_index()] - 1] = *k; positions[k.into_index()] -= 1; } for (i, k) in tmp.iter().enumerate() { array[i] = *k; } } }
Bucket Sort
TODO: bucket sort with LinkedList and Insertion Sort / Counting sort / Olog(n)
Exercises
#![allow(unused)] fn main() { mod exercises { // Ex 1, Is stable_counting_sort stable? Yes // Ex 2, Worst case for bucket_sort? O(n^2) if insertion_sort is used for buckets, O(n) if // counting sort is used // Ex 3, bucket_sort using counting_sort for buckets, hypotesis on k? } }
Linked List
#![allow(unused)] fn main() { pub struct LinkedList<T> { pub value: T, pub next: Option<Rc<LinkedList<T>>>, } }
Queue
Linked List Implementation
Rust
Java
import java.util.Optional;
public class Queue<T> {
Node<T> head, tail;
public void enqueue(T value) {
var node = new Node<T>(value);
if (tail == null) {
head = node;
tail = node;
} else {
tail.next = node;
tail = tail.next;
}
}
public Optional<T> dequeue() {
if (head == null)
return Optional.empty();
var result = head.value;
head = head.next;
if (head == null)
tail = null; // Queue is empty
return Optional.of(result);
}
}
Array Implementation
Rust
#![allow(unused)] fn main() { pub struct Queue<T> { buffer: Box<[T]>, start: usize, end: usize, size: usize, } impl<T> Queue<T> { pub fn from(buffer: Box<[T]>) -> Self { Self { buffer, start: 0, end: 0, size: 0, } } pub fn len(&self) -> usize { self.size } pub fn enqueue(&mut self, value: T) -> Result<(), &'static str> { if self.size == self.buffer.len() { return Err("The Queue is full"); } self.buffer[self.end] = value; self.size += 1; self.end = (self.end + 1) % self.buffer.len(); Ok(()) } pub fn dequeue(&mut self) -> Option<&T> { if self.size == 0 { return None; } let result = self.buffer.get(self.start); self.start = (self.start + 1) % self.buffer.len(); self.size -= 1; result } } impl<T: Copy> Iterator for Queue<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { self.dequeue().and_then(|&v| Some(v)) } } }
Java
import java.util.Optional;
public class ArrayQueue<T> {
Object[] queue;
Integer head = 0, tail = 0, size = 0;
public ArrayQueue(Integer size) {
queue = new Object[size];
}
public void enqueue(T value) throws IndexOutOfBoundsException {
if (size == queue.length)
throw new IndexOutOfBoundsException();
queue[tail] = value;
tail++;
if (tail >= queue.length)
tail = 0;
}
public Optional<Object> pop() {
if (size == 0)
return Optional.empty();
var result = queue[head];
head++;
if (head >= queue.length)
head = 0;
return Optional.of(result);
}
}
Stack
Linked List Implementation
Rust
Java
import java.util.Optional;
public class Stack<T> {
Node<T> top;
public void push(T value) {
top = new Node<T>(value, top);
}
public Optional<T> pop() {
if (top == null)
return Optional.empty();
var result = top.value;
top = top.next;
return Optional.of(result);
}
}
Array Implementation
Rust
#![allow(unused)] fn main() { pub struct Stack<T> { buf: Box<[T]>, len: usize, } impl<T> From<Vec<T>> for Stack<T> { fn from(value: Vec<T>) -> Self { Self { buf: value.into_boxed_slice(), len: 0, } } } impl<T> Stack<T> { pub fn len(&self) -> usize { self.len } pub fn push(&mut self, value: T) -> Result<(), &'static str> { if self.len == self.buf.len() { return Err("Pirla, non hai piu' spazio per i piatti!"); } self.buf[self.len] = value; self.len += 1; Ok(()) } pub fn pop(&mut self) -> Option<&T> { if self.len == 0 { return None; } self.len -= 1; self.buf.get(self.len) } } impl<T: Copy> Iterator for Stack<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { self.pop().and_then(|&v| Some(v)) } } }
Java
import java.util.Optional;
public class ArrayStack<T> {
Object[] stack;
Integer top;
public ArrayStack(Integer size) {
stack = new Object[size];
top = 0;
}
public Boolean isFull() {
return top == stack.length - 1;
}
public void push(T value) throws IndexOutOfBoundsException {
if (isFull())
throw new IndexOutOfBoundsException();
stack[top] = value;
top++;
}
public Optional<Object> pop() {
if (top == 0)
return Optional.empty();
var result = stack[top];
top--;
return Optional.of(result);
}
Red Black Tree
#include <stdio.h>
#include <stdlib.h>
typedef enum { Red, Black } Color;
typedef struct RBTree RBTree;
struct RBTree {
int value;
Color color;
struct RBTree *left, *right, *parent;
};
RBTree *FAKE_LEAF = &(RBTree){0, Black, NULL, NULL, NULL};
void rotate_left(RBTree *x) {
RBTree *parent = x->parent, *y = x->right;
RBTree *alpha = x->left, *beta = y->left, *gamma = x->right;
if (parent != NULL) {
if (parent->left == x)
parent->left = y;
else
parent->right = y;
}
y->parent = parent;
y->left = x;
x->parent = y;
x->left = alpha;
x->right = beta;
alpha->parent = x;
beta->parent = x;
}
void rotate_right(RBTree *x) {
RBTree *parent = x->parent, *y = x->left;
RBTree *alpha = y->left, *beta = y->right, *gamma = x->right;
if (parent != NULL) {
if (parent->left == x)
parent->left = y;
else
parent->right = y;
}
y->parent = parent;
y->left = alpha;
y->right = x;
alpha->parent = y;
x->parent = y;
x->left = beta;
x->left->parent = y;
}
void fix(RBTree *tree) {
if (tree->parent == NULL) {
tree->color = Black;
return;
}
if (tree->parent->parent == NULL || tree->parent->color == Black)
return;
RBTree *grandpa = tree->parent->parent, *father = tree->parent;
RBTree *uncle = grandpa->left == father ? grandpa->right : grandpa->left;
if (uncle->color == Red) {
father->color = Black;
uncle->color = Black;
grandpa->color = Red;
fix(grandpa);
} else if (father->right == tree) {
rotate_left(father);
fix(father);
} else if (father->left == tree) {
if (grandpa->left == father) {
rotate_right(grandpa);
grandpa->color = Red;
father->color = Black;
} else {
rotate_left(grandpa);
grandpa->color = Red;
father->color = Black;
fix(tree);
}
}
}
void insert_with_parent(RBTree **tree, RBTree *parent, int value) {
if (*tree == FAKE_LEAF) {
*tree = malloc(sizeof(RBTree));
**tree = (RBTree){value, Red, FAKE_LEAF, FAKE_LEAF, parent};
fix(*tree);
} else if (value < (*tree)->value)
insert_with_parent(&(*tree)->left, *tree, value);
else
insert_with_parent(&(*tree)->right, *tree, value);
}
void insert(RBTree **tree, int value) {
insert_with_parent(tree, NULL, value);
if ((*tree)->parent != NULL)
*tree = (*tree)->parent;
}
void visit(RBTree *tree, int layer) {
for (int _ = 0; _ < layer; _++)
printf(" ");
if (tree == FAKE_LEAF) {
printf("\x1b[1;30m\x1b[1;47m-\x1b[0m\n");
return;
}
if (tree->color == Red)
printf("\x1b[1;31m");
else
printf("\x1b[1;30m\x1b[1;47m");
printf("%d\x1b[0m\n", tree->value);
visit(tree->left, layer + 1);
visit(tree->right, layer + 1);
}
int main() {
RBTree *tree = FAKE_LEAF;
int values[] = {11, 14, 15, 2, 1, 7, 5, 8, 4};
int SIZE = 9;
for (int *value = values; value < values + SIZE; value++)
insert(&tree, *value);
visit(tree, 0);
}
Assimoatica della probabilità
La probabilità si basa sugli assiomi introdotti da Andrey Kolmogorov nel 1933. Uno schema probabilistico, o modello probabilistico, è composto da 3 oggetti .
In alternativa al punto 3.
è chiamato spazio degli eventi elementari (o spazio campionario) è un evento, ovvero, una domanda binaria sull'esito dell'esperimento è l'algebra degli eventi è la probabilità
Conseguenze degli assiomi
TODO: dimostrare le proprietà sotto
Monotonicità
Probabilità dell'insieme vuoto
Regola del complemento
Limite numerico
Altre conseguenze
Costruzione di
Sia ottenuta restringendo agli eventi elementari
Per il terzo assioma
Probabilità uniforme
Si ha probabilità uniforme quando
Indipendenza
Spazio di probabilità prodotto
Siano e due schemi probabilistici (Es. lancio di una moneta e misura della temperatura a Rio). Ora si considera l'esperimento congiunto
La scelta naturale per la probabilità è la probabilità prodotto
Si può osservare che:
Se sono le probabilità uniformi su allora , probabilità prodotto, è la probabilità uniforme su .
Infatti
soddisfa le seguenti condizioni di compatibilità:
- Sia un evento che posso decidere osservando l'esperimento descritto solo da , osservo che con , allora
- Allo stesso modo, se è un evento deciso osservando solo , ovvero con , si ha
Nello schema di probabilità prodotto, se è deciso solo da e è deciso solo da , allora
In generale, dato lo schema probabilistico , due eventi sono indipendenti quando
Indipendenza di 3 eventi
Dato lo schema probabilistico , siano ci sono almeno due modi di definire l'indipendenza di 3 eventi:
-
Indipendenza a coppie, per cui
-
Indipendenza a terna, per cui
Si dimostra che l'indipendenza di tipo non implica e l'indipendenza di tipo non implica , per questo, quando si darà per assunta l'ipotesi di indipendenza si considerano sia l'indipendenza a coppie sia l'indipendenza a terna come vere.
Indipendenza di eventi
Sia uno schema probabilistico, sono indipendenti quando presa una qualunque sottofamiglia di la probabilità
Schema di Bernoulli
Lo schema di Bernoulli rappresenta un esperimento binario ripetutto volte:
- tradizionalmente lanci di moneta non necessariamente equa
- la trasmissione di bit su un cavo con disturbi (1 mi indica che il bit è arrivato corretamente, 0 altrimenti), schema in cui la probabilità di errore (di 0) deve essere bassa
Si codificano i risultati con (per comodità dei calcoli successivamente)
La scelta naturale è la probabilità prodotto su singolo lancio, dove indica la "truccatura" della moneta
Lo schema si indica con
| n | |
|---|---|
| 1 | |
| 2 | |
| 3 |
In generale
Probabilità condizionata
Sia uno schema probabilistico e eventi, si definisce la probabilità condizionata come:
Sia la probabilità uniforme, allora
Probabilità composte
Sia uno schema probabilistico, e siano eventi
Probabilità totali
Sia uno schema probabilistico, e siano
Formula di Bayes
Variabili aleatorie
Sia uno schema probabilistico, è una variabile aleatoria. Per distribuzione di una variabile aleatoria s'intende l'istogramma che rappresenta le probabilità dei valori in
La probabilità su induce una probabilità su tramite , per cui , equivalentemente , per cui è la distrubuzione di
Valore di attesa
Linearità
Varianza
Covarianza
Variabile aleatoria geometrica
Usata tipicamente in teoria dell'affidabilità. Si ipotizza un macchinario che opera a cicli, e la trovi anche qui.
Siano
- la probabilità di rottura ad ogni ciclo
- il tempo di rottura (dopo quanti cicli si è rotto)
Per cui , quindi la v.a. geometrica è uno schema di Bernoulli con infiniti lanci e probabilità prodotto,
Distribuzione
Valore di attesa
Dimostrazione
Varianza
Perdita di memoria
Sia la funzione di sopravvivenza tale che
Ora possiamo determinare che , dato che
Variabile aleatoria binomiale negativa
Variabile aleatoria di Poisson
Usata spesso in teoria delle code, e la trovi anche qui.
Sia un intervallo piccolo di tempo, si ha che la probabilità
Arrivi in intervalli di tempo disgiunti sono indipendenti. Ora si consideri l'intervallo di tempo unitario , quindi suddiviso in intervalli
X_i = \text{# di arrivi nell'intervallo } \biggl(\frac{i-1}{n}, \frac{i}{n}\biggl) = \begin{cases} 1 & \text{con probabilita' } & \frac{\lambda}{n} \ 0 & \text{con probabilita' } & 1 - \frac{\lambda}{n} \end{cases} \implies \ \implies X_i \sim \text{Bernoulli}\biggl(\frac{\lambda}{n}\biggl)
Per cui
X^{(n)} = \text{# di arrivi nell'intervallo } [0, 1] = \sum\limits_{i = 1}^n X_i \implies X^{(n)} \sim \text{Bin}\biggl(n, \frac{\lambda}{n}\biggl)
Teorema di Poisson
Siano , con grande abbastanza. Fissando , allora
TODO: Dimostrazione
Distribuzione
TODO: Dimostrazione distribuzione
Valore di attesa
Dimostrazione
Varianza
Dimostrazione
Complementare
TODO
Variabile aleatoria multinomiale
Distribuzione marginale con
Distribuzione di condizionata a
Valore di attesa di
Varianza di
Covarianza di
Dovrebbe venire < 0
Problema degli accoppiamenti
Dato uno schema probabilistico. Sia biettiva, allora è un punto fisso se , calcolare la probabilità che una permutazione casuale non abbia punti fissi.
- è la probabilità uniforme su
Codifichiamo l'evento di cui si vuole calcolare la probabilità
Questo è un problema per cui il passaggio a complemento si pone come una buona soluzione, per cui
Ora è possibile scrivere
Dato che, per simmetria, gli eventi hanno la stessa cardinalità, basta calcolare
Il problema è che gli eventi non sono disgiunti, quindi bisogna usare il PIE per calcolare la cardinalità dell'unione, per cui servono le intersezioni
È possibile generalizzare per l'intersezione di eventi, con
Ora è possibile usare il PIE per ricavare la sommatoria completa
TODO: completare
Legge dei grandi numeri
Disuguaglianza di Markov
Disuguaglianza di Čebyšëv
Legge dei grandi numeri
Metodo Montecarlo
Databases

Download the introduction presentation
View the presentation on proofs or download it. The links refer to the slides of prof. Perelli and don't work on the website: you have to download the pdf in the same folder with the course's slides for the links to work.
Schema
An attribute is a pair; we can define the function on a set of names, which associates to each name a specific domain (different attributes can have the same domain)
A relation schema is a set of attributes
Tuples & instances
PDF 7 slide 3 Given a relation schema , a tuple on is a function such that
Given a relation schema , a subset and a tuple on , the reduction of on is defined as
PDF 7 slide 4 Given a relation schema , a subset and tuples on
PDF 7 slide 5 Given a relation schema and tuples on , a set is an instance of
Functional dependencies
Given a relation schema and we have that is a functional dependency on (noted as )
Given a relation schema and a functional dependency defined on we say that an instance of satisfies the functional dependency if
Instance legality & closure
Given a relation schema and a set of functional dependencies defined on , an instance of is legal if it satisfies every dependency in
Given a relation schema and a set of functional dependencies defined on , the closure of is the set of functional dependencies that are satisfied by every legal instance of
doesn't necessarily have to be in
Proof
By definition is legal if it satisfies every dependency given , every legal instance of satisfies
Keys
Given a relation schema and a set of functional dependencies on , is a key of if
means proper subset, which implies that
Trivial dependencies
Given a schema and , we have that every instance of satisfies the dependency
Proof
Given an instance of we have that
by definition as we have that
by definition
As we have that satisfies
Decomposition
Given a schema and a set of functional dependencies on , we have that
Proof
PDF 8 slide 3 is a set of functional dependencies on such that
- (refelxivity)
- (augmentation)
- (transitivity)
PDF 8 slide 6 derivates
- (union)
- (decomposition)
- (pseudotransitivity)
Derivates (Proofs)
Union
LaTeX
by augmentation by transitivity
Decomposition
by transitivity
Pseudotransitivity
by augmentation by transitivity
RFRX \subseteq RXF(X)^+_FX \subseteq (X)^+_F
Proof
\forall A \in XX \to A \in F^A \impliesA \in (X)^+_F \implies X \subseteq (X)^+_F(X)^+_FF^A(X)^+_FF^+
Lemma of closure
Let RFR
Proof
X \to Y \in F^A \impliesX \to A \in F^A ; \forall A \in Y \impliesA \in (X)^+_F ; \forall A \in Y \implies Y \subseteq (X)^+_FY \subseteq (X)^+_F \implies A \in (X)^+_F ; \forall A \in Y \impliesX \to A \in F^A ; \forall A \in Y \impliesX \to Y \in F^A
F^+ = F^ARFRF^+ = F^A
Proof
Let F_iFiF_0 = F
F^A \subseteq F^+
Base case
F_0 = F \subseteq F^+ \implies F_0 \subseteq F^+
Inductive step
F_i \subseteq F^+ \implies F_{i + 1} \subseteq F^+X \to Y \in F_{i + 1}X \to Y \in F_i \impliesX \to Y \in F^+X \to Y \in F_{i + 1} \setminus F_iX \to Y has been optained through one of the axioms
F^A \subseteq F^+
Reflexivity
Y \subseteq X \impliesX \to YX \to Y \in F^+
Augmentation
Z \subseteq R, X = ZV, Y = ZW \land V \to W \in F_it_1, t_2 \in rRt_1[X] = t_2[X] \implies (t_1[V] = t_2[V] \impliest_1[W] = t_2[W]) \land t_1[Z] = t_2[Z] \implies t_1[Y] = t_2[Y]
Transitivity
X \to Z, Z \to Y \in F_i \implies\forall \text{ legal } r \text{ of } R, \forall t_1, t_2 \in r, t_1[X] = t_2[X] \implies t_1[Z] = t_2[Z] \implies t_1[Y] = t_2[Y]t_1[X] = t_2[X] \implies t_1[Y] = t_2[Y] \implies X \to Y \in F^+
F^+ \subseteq F^AX \subseteq Rr = \set{t_1, t_2}Rr(X)^+_FR \setminus (X)^+_Ft_1t_2rV \to W \in FV, W \neq \varnothingV \nsubseteq (X)^+_F \implies \exists A \in V : A \in R \setminus (X)^+_F \implies t_1[V] \neq t_2[V] \implies rV \to WV \subseteq (X)^+_FW \subseteq (X)^+_F \implies t_1[V] = t_2[V] \land t_1[W] = t_2[W] \implies rV \to WW \nsubseteq (X)^+_F \implies \exists A \in W : A \in R \setminus (X)^+_F \implies t_1[V] = t_2[V] \land t_1[W] \neq t_2[W]
F^+ \subseteq F^ArV \to W\exists V \to W \in FrV \to WV \subseteq (X)^+_F \impliesX \to V \in F^AA \in W \impliesV \to A \in F^AX \to A \in F^A \impliesA \in (X)^+_F which is a contraddiction
Legality
In the first 2 cases rV \to W \in F\implies rR
F^+ \subseteq F^AX \to Y \in F^+X \subseteq (X)^+_F \impliest_1[X] = t_2[X] \impliesrt_1[Y] = t_2[Y] \impliesY \subseteq (X)^+_F \implies X \to Y \in F^A
F^+ = F^AF_i \subseteq F^+ : \forall i \in \mathbb{N}F^+ \subseteq F^AF^+ = F^A
3NF
Given a relation schema RFRR\forall X \to A \in F^+ : A \notin XAX is superkey
3NF pt.2
Let RFRA \in RK\exists X \subset R : A \notin X \land X \to A \in F \land X \subset KAA \in RK\exists X \subset R : A \notin X \land X \to A \in F \land K \to X \in FXAX \subset RX \neq RR \to R \in F^A = F^+
3NF pt.3
Given a schema RFRR\forall X \to A \in F^+ : A \notin XAX is superkey
Proof
TODO: I have it, I just have to write it out in \LaTeXRFRRF -->
BCNF (Boyce-Codd)
A relation schema RF is a superkey. A relation that respects Boyce-Codd Normal Form is also in 3NF, but the opposite is not true.
(X)^+_F
def clousure(R, F, X):
Z = X
S = { A ∈ R | Y → V ∈ F ∧ Y ⊆ Z ∧ A ∈ V }
if S ⊆ Z:
return Z
return closure(R, F, Z ∪ S)
(X)^+_FXFR
Proof
Let's consider Z_i, S_iZSiZ_f, S_f \mid S_f \subseteq Z_fZ, SZ_i \subseteq (X)^+_F
Z_i \subseteq (X)^+_F
Base case
Inductive step Z_i \subseteq (X)^+F \implies Z{i + 1} \subseteq (X)^+FZ_i \subseteq (X)^+F \implies Z{i + 1} \subseteq (X)^+FS_i = \set{A \in R \mid Y \to V \in F \land Y \subseteq Z_i \land A \in V}Z{i + 1} = Z_i \cup S_iA \in Z{i + 1}A \in Z_i \impliesA \in (X)^+_FA \in S_i \implies\exists Y \to V \in F \mid Y \subseteq Z_i \land A \in V \impliesY \subseteq (X)^+_F \impliesX \to Y \in F^AY \to A \in F^A \impliesX \to A \in F^A \impliesA \in (X)^+_F
(X)^+_F \subseteq Z_fZ_fr = \set{t_1, t_2}RrZ_fR \setminus Z_ft_1t_2rV \to W \in FV, W \neq \varnothingV \nsubseteq Z_f \implies \exists A \in V : A \in R \setminus Z_f \implies t_1[V] \neq t_2[V] \implies rV \to WV \subseteq Z_fW \subseteq Z_f \impliest_1[V] = t_2[V] \land t_1[W] = t_1[W] \impliesrV \to WW \nsubseteq Z_f \impliest_1[V] = t_2[V] \land t_1[W] \neq t_2[W]
(X)^+_F \subseteq Z_f\exists V \to W \in F : rV \to W \impliesV \subseteq Z_f \land V \to W \in F \land A \in W \impliesS_f, : A \in Z_f which is a contraddiction
Legality
In the first 2 cases rV \to W \in F\implies rR
(X)^+_F \subseteq Z_fA \in (X)^+_FX \to A \in F^A = F^+r\implies rX \to YX \subseteq Z_f \implies t_1[X] = t_2[X] \impliest_1[A] = t_2[A] \impliesA \in Z_f
Z_f = (X)^+_FZ_i \subseteq (X)^+_F ; \forall i \in \mathbb{N}(X)^+_F \subseteq Z_fZ_f = (X)^+_F
Intersection Rule
Given a relation scheme RFRRRX \to R \in F^+RR is in 3NF
Decomposition
Let R\rhoR
Equivalence
Let FGF \implies F^+ = F^+ \implies F \equiv FF \equiv G \implies F^+ = G^+ \implies G^+ = F^+ \implies G \equiv FF \equiv G \land G \equiv H \implies F^+ = G^+ \land G^+ = H^+ \implies F^+ = H^+ \implies F \equiv HFG
F \subseteq G^+ \implies F^+ \subseteq G^+
Base case
F_0 = F \subseteq G^+ \implies F_0 \subseteq G^+
Inductive Step
F_i \subseteq G^+ \implies F_{i + 1} \subseteq G^+X \to Y \in F_{i + 1} \implies X \to YY \subseteq X \impliesX \to YX \to Y \in G^+\exists Z \subseteq R, V \to W \in F_i \mid X = ZV, Y = ZW
- transitivity
TODO
Preserving F
Let RFR\rho = \set{R_1, R_2, ..., R_k}R\rhoFGG \subseteq F^+ \implies G^+ \subseteq F^+F \subseteq G^+
Dependency preservation
def preserves_dependencies(R, F, ρ):
for X → Y ∈ F:
if Y ⊈ closure_G(R, F, ρ, X):
return false
return true
This algorithm is enough as we just have to check wether F \subseteq G^+X \to Y \in FX \to Y \in G^+ = G^A \iffY \subseteq (X)^+_G
(X)^+_GRFR\rho = \set{R_1, R_2, ..., R_k}RX \subseteq R(X)^+_G
Z_f \subseteq (X)^+_GZ_i, S_iZSiZ_0 = XS_f \subseteq Z_fZS -->
Base case
Z_0 = X \subseteq (X)^+_G \implies Z_0 \subseteq (X)^+_G by HP
Inductive step
Z_i \subseteq (X)^+G \implies Z{i+1} \subseteq (X)^+GS_i = \bigcup\limits{j = 1}^k (Z_i \cap R_j)^+F \cap R_jA \in Z{i + 1} = Z_i \cup S_i \implies \exists j : A \in (Z_i \cap R_j) \cap R_j \implies Z_i \cap R_j \to A \in G^AZ_i \subseteq (X)^+_G \implies X \to Z_i \in G^AZ_i = (Z_i \cap R_j) \cup VX \to Z_i \cap R_j \in G^A \impliesX \to A \in G^A
X \subseteq Y \implies (X)^+_F \subseteq (Y)^+_FX \subseteq Y \implies Y \to X \in F^AA \in (X)^+_F \impliesX \to A \in F^A \impliesY \to A \in F^A \ \impliesA \in (Y)^+_F
(X)^+_G \subseteq Z_fX \subseteq Z_f \implies (X)^+_G \subseteq (Z_f)^+_GZ_f = (Z_f)^+_GA \in S' = \set{A \in R \mid V \to W \in G \land V \subseteq Z_f \land A \in W} \implies \exists V \to W \in G : V \subseteq Z_f \land A \in W \implies \exists R_j \in \rho : VW \subseteq R_j \implies V \subseteq Z_f \cap R_j \land A \in R_j \implies A \in (Z_f \cap R_j)^+_F \cap R_j \implies A \in S_f \implies A \in Z_f
Loseless join
r \subseteq m_{\rho}(r)t \in r \implies t[R_i] \in \pi_{R_i}(r) ; \forall R_i \in \rho\mathop{\bowtie}\limits_{i = 1}^k \pi_{R_i}(r) = \set {\bigcup\limits_{i = 1}^k p_i[R_i] \mid p_i[R_i] \in \pi_{R_i}(r) \land \bigcup\limits_{i = 1}^k p_i[R_i] \text{ is a function}}\forall t \in r, ; t = \bigcup\limits_{i = 1}^k t[R_i]\rhoR = \bigcup\limits_{i = 1}^k R_it \in r \implies tt = \bigcup\limits_{i = 1}^k t[R_i] \in \mathop{\bowtie}\limits_{i = 1}^k \pi_{R_i}(r) = m_{\rho}(r) \implies t \in m_{\rho}(r)\forall t \in r, ; t = \bigcup\limits_{i = 1}^k t[R_i] = \mathop{\bowtie}\limits_{i = 1}^k \set{ t[R_i] }t \in r \impliest[R_i] \in \pi_{R_i}(r) ; \forall R_i \in \rho \implies \set{ t[R_i] } \subseteq \pi_{R_i}(r) ; \forall R_i \in \rhot = \mathop{\bowtie}\limits_{i = 1}^k \set{ t[R_i] } \subseteq \mathop{\bowtie}\limits_{i = 1}^k \pi_{R_i}(r) = m_{\rho}(r) \implies t \in m_{\rho}(r)\forall t \in rt[R_i], : R_i \in \rhot \in \set{ t[R_1] } \bowtie ... \bowtie \set{ t[R_k] } \subseteq \pi_{R_1}(r) \bowtie ... \bowtie \pi_{R_k}(r) = m_{\rho}(r) -->
\pi_{R_i}(m_{\rho}(r)) = \pi_{R_i}(r)t_{R_i} \in \pi_{R_i}(m_{\rho}(r))t_{R_i} \in \pi_{R_i}(r)t \in r \impliest[R_i] \in \pi_{R_i}(r) ; \forall R_i \in \rho\pi_{R_i}(m_{\rho}(r)) = \set{q[R_i] \mid q \in \mathop{\bowtie}\limits_{i = 1}^k \pi_{R_i}(r)}
\pi_{R_i}(r) \subseteq \pi_{R_i}(m_{\rho}(r))t \in r \implies t \in m_{\rho}(r) \implies t[R_i] \in \pi_{R_i}(m_{\rho}(r))
\pi_{R_i}(m_{\rho}(r)) \subseteq \pi_{R_i}(r)q \in \mathop{\bowtie}\limits_{i = 1}^k \pi_{R_i}(r) \impliesq = \mathop{\bowtie}\limits_{i = 1}^k \set{ p_i[R_i] } \mid p_i \in r \impliesqq[R_i] = p_i[R_i]p_i \in r \implies p_i[R_i] \in \pi_{R_i}(r)q[R_i] \in \pi_{R_i}(r)\exists p_1, p_2, ..., p_k \in r \mid p_i[R_i] \in \pi_{R_i}(r) ; \forall i = 1,..., kt_{R_i} \in \pi_{R_i}(m_{\rho}(r)) \iff \exists t' \in m_{\rho}(r) : t'[R_i] = t_{R_i} \iff\iff \exists t_1, ..., t_k \in r : t'[R_j] = t_j[R_j] \quad \forall R_j \in \rhot_{R_i} = t[R_i] \in \pi_{R_i}(r) -->
m_{\rho}(m_{\rho}(r)) = m_{\rho}(r)m_{\rho}(m_{\rho}(r)) = \mathop{\bowtie}\limits_{i = 1}^k \pi_{R_i}(m_{\rho}(r)) = \mathop{\bowtie}\limits_{i = 1}^k \pi_{R_i}(r) = m_{\rho}(r)m_{\rho}(m_{\rho}(r)) = \pi_{R_1}(m_{\rho}(r)) \bowtie ... \bowtie \pi_{R_k}(m_{\rho}(r)) = \pi_{R_1}(r) \bowtie ... \bowtie \pi_{R_k}(r) = m_{\rho}(r)m_{\rho}(m_{\rho}(r)) = \pi_{R_1}(m_{\rho}(r)) \bowtie ... \bowtie \pi_{R_k}(m_{\rho}(r)) = \pi_{R_1}(r) \bowtie ... \bowtie \pi_{R_k}(r) = m_{\rho}(r)t_{R_i} \in \pi_{R_i}(r)t_{R_i} \in \pi_{R_i}(m_{\rho}(r))t_{R_i} \in \pi_{R_i}(r) \land t' \in rt'[R_i]t'[R_i] \in t_{R_i} -->
Loseless join pt.2
PDF 15 slide 15 Given \rho = \set{R_1, R_2, ..., R_k}r|R|kija_jA \in R_{i}b_{ij}
def has_looseless_join(R, F, ρ):
while !(∃ t ∈ r | ∀ A ∈ R, t[A] = a) and r changed:
for X → Y ∈ F:
for t1 ∈ r:
for t2 ∈ r:
if t1[X] = t2[X] and t1[Y] != t2[Y]:
for A ∈ Y:
if t1[A] = a:
t2[A] = t1[A]
else:
t1[A] = t2[A]
return ∃ t ∈ r | ∀ A ∈ R, t[A] = a
Correctness
Let RFR\rho = \set{R_1, R_2, ..., R_k}R\rhor = m_{\rho}(r) \iff rar = m_{\rho}(r) \implies ra\LaTeX
Minimal cover
Let RFRFG \equiv F\forall X \to Y \in G, |Y| = 1\forall X \to A \in G, \nexists X' \subset X \mid G \equiv (G - \set{X \to A}) \cup \set{X' \to A}\nexists X \to A \in G \mid G \equiv G - \set{X \to A}
Minimal cover (step 1)
F_1 = \set{X \to A \mid X \to Y \in F \land A \in Y}F \overset{A}{\to} F_1F_1 \overset{A}{\to} F_1^A \implies F \subseteq F_1^AF_1 \overset{A}{\to} FF \overset{A}{\to} F^A \implies F_1 \subseteq F^AF \equiv F_1
Minimal cover (step 2)
Given X \to A \in F_1, X' \subset X \land X' \to A \in F_1^+ \implies F_2 = (F_1 \setminus \set{X \to A}) \cup \set{X' \to A}X' \subseteq X \implies X \to X' \in F_1^+ \land X \to X' \in F_2^+X \to A \in F_1X \to A \in F_2 \implies X \to A \in F_2^+X \to A \notin F_2 \implies X \to X' \in F_2^+ \land X' \to A \in F_2^+ \implies X \to A \in F_2^+X \to A \in F_2X \to A \in F_1 \implies X \to A \in F_1^+X \to A \notin F_1 \implies X \to A \in F_1^+F_2 \equiv F_1 \implies F \equiv F_2\equiv relationship
Minimal cover (step 3)
X \to A \in F_2, ; A \in (X)^+{F_2 \setminus \set{X \to A}} \implies F_3 = F_2 \setminus \set{X \to A}X \to A \in F_2X \to A \in F_3 \implies X \to A \in F_3^+X \to A \notin F_3 \implies X \to A \in F_3^+A \in (X)^+{F_3}X \to A \in F_3X \to A \in F_2 \implies X \to A \in F_2^+X \to A \notin F_2F_3 = F_2 \setminus \set{X \to A}F_2 \equiv F_3 \implies F \equiv F_3
Decomposition
def decomposition(R, F: minimal cover):
S = ∅
ρ = ∅
for A ∈ R | ∄ X → Y ∈ F : A ∈ XY:
S = S ∪ {A}
if S != ∅:
R = R - S
ρ = ρ ∪ {S}
if ∃ X → Y ∈ F | XY = R:
ρ = ρ ∪ {R}
else:
for X → A ∈ F:
ρ = ρ ∪ {XA}
Decomposition pt.2
Let RFR\rhoR\rho\rhoF
Azienda 1
Si vuole sviluppare un sistema informativo per la gestione dei dati sul personale di una certa azienda costituita da diversi dipartimenti. Durante la fase di raccolta dei requisiti è stata prodotta la specifica dei requisiti mostrata di seguito. Si chiede di iniziare la fase di Analisi dei requisiti ed in particolare di:
- raffinare la specifica dei requisiti eliminando inconsistenze, omissioni o ridondanze e produrre un elenco numerato di requisiti il meno ambiguo possibile
- produrre un diagramma UML delle classi concettuale che modelli i dati di interesse, utilizzando solo i costrutti di
classe,associazione,attributo
Requisiti
I dati di interesse per il sistema sono impiegati, dipartimenti, direttori dei dipartimenti e progetti aziendali.
-
Di ogni impiegato interessa conoscere il nome, il cognome, la data di nascita e lo stipendio attuale, il dipartimento al quale afferisce (esattamente uno, con la rispettiva data di afferenza).
-
Di ogni dipartimento interessa conoscere il nome, il numero di telefono del centralino
- Di ogni dipartimento interessa conoscere inoltre il direttore, che è uno degli impiegati dell’azienda.
-
Il sistema deve permettere di rappresentare i progetti aziendali nei quali sono coinvolti i diversi impiegati.
-
Di ogni progetto interessa il nome ed il budget.
-
Ogni impiegato può partecipare ad un numero qualsiasi di progetti.
UML (opzione 1)
Osservazioni
Questa è l'opzione più "complessa"
- Un dipartimento non deve avere per forza un dirigente assegnato (quindi
0..1) - Un impiegato può dirigere più dipartimenti (non afferisce al dipartimento che dirige, ci potrebbe essere un dipartimento apposta per i dirigenti, quindi
0..*) - La classe
Afferenzaci serve per tenere uno storico dei dipartimenti in cui ha lavorato un impiegato - Usiamo la classe
Partecipazioneper i progetti perché un impiegato può lavorare ad un progetto più volte in periodi diversi di tempo (N.B. è fondamentale avere come attributidata_inizioedata_fine, altrimenti l'utilizzo della classe non regge in questo contesto) - Usare il tipo
Stringaper l'attributotelefononon va bene, ma la soluzione originale lo includeva e preferisco attenermi a quella
classDiagram
class Impiegato {
nome: Stringa
cognome: Stringa
data_di_nascita: Data
stipendio: Razionale >= 0
}
class Impiegato["fa:fa-users Impiegato"]
class Dipartimento {
nome: Stringa
telefono: Stringa
}
class Dipartimento["fa:fa-building Dipartimento"]
class Afferenza {
data: Data
}
class Progetto {
nome: Stringa
budget: Razionale >= 0
}
class Progetto["fa:fa-wrench Progetto"]
class Partecipazione {
data_inizio: Data
data_fine: Data
}
Impiegato "1..1" -- "0..*" Partecipazione : impiegato_partecipante
Partecipazione "0..*" -- "1..1" Progetto : progetto_partecipazione
Impiegato "0..1" -- "0..*" Dipartimento : dirige
Afferenza "1..*" -- "1..1" Impiegato : impiegato_afferente
Afferenza "0..*" -- "1..1" Dipartimento : dipartimento_afferenza
UML (opzione 2)
Osservazioni
Questa è l'opzione più "minimale"
- Un dipartimento non deve avere per forza un dirigente assegnato (quindi
0..1) - Un impiegato può dirigere al più un dipartimento
- L'impiegato afferisce ad un solo dipartimento, quindi possiamo mettere la
data_di_afferenzacome attributo dell'impiegato - Un dipendente o partecipa ad un determinato progetto o non vi partecipa, la relazione è binaria e non serve una classe
- Usare il tipo
Stringaper l'attributotelefononon va bene, ma la soluzione originale lo includeva e preferisco attenermi a quella
classDiagram
class Impiegato {
nome: Stringa
cognome: Stringa
data_di_nascita: Data
stipendio: Razionale >= 0
data_di_afferenza: Data
}
class Impiegato["fa:fa-users Impiegato"]
class Dipartimento {
nome: Stringa
telefono: Stringa
}
class Dipartimento["fa:fa-building Dipartimento"]
class Progetto {
nome: Stringa
budget: Razionale >= 0
}
class Progetto["fa:fa-wrench Progetto"]
Impiegato "0..*" -- "0..*" Progetto : partecipa a
Impiegato "0..1" -- "0..1" Dipartimento : dirige
Impiegato "0..*" -- "1..1" Dipartimento : afferisce a
Voli Aerei 1
Requisiti
I dati di interesse per il sistema sono voli, compagnie aeree ed aeroporti.
- Dei voli interessa rappresentare codice, durata, compagnia aerea ed aeroporti di partenza e arrivo.
- Degli aeroporti interessa rappresentare codice, nome, città (con nome e numero di abitanti) e nazione.
- Delle compagnie aeree interessa rappresentare nome, anno di fondazione, e la città in cui ha sede la direzione.
TODO: durata minima di un volo durata: [(ore: intero >= 1, minuti: intero >= 0), (ore: intero >= 0, minuti: intero >= 1)] compagnia aerea più vecchia? 1912 tecnicamente, ma mettiamo 1906, se gli aerei non esistono, non possono esistere le compagnie aere
Volo
- codice, composto dalle 2 lettere della compagnia, dal numero di volo (questo numero può variare da 1 a 4 cifre e serve a distinguere ogni volo gestito dalla compagnia aerea)
- duarata (vedere tabella sotto)
- compagnia aerea
- aeroporto di partenza
- aeroporto di arrivo
- non interessano i posti disponibili, dato che non è una delle metriche di cui la IATA tiene traccia
- potrebbe interessare il ritardo
Una classificazione arbitraria della durata di un volo secondo Wikipedia
| tipo di volo | durata |
|---|---|
| corto raggio | meno di 3 ore (internazionale) |
| medio raggio | da 3 a 6 - 8 ore |
| lungo raggio | da 6 a 12 ore |
| ultra-lungo raggio | più di 12 ore |
Il volo più lungo è stato di circa 20 ore, ma non è importante dare un limite massimo alla durata di un volo
Aeroporto
- nome ("Paperopoli" pare lecito qui)
- codice, qui useremo il Il codice aeroportuale IATA ("Paperopoli" qui non va decisamente bene), una stringa lunga 3 di lettere maiuscole
- città, perché sì
- nazione, perché sì
Compagnia aerea
- nome ("Paperopoli" pare lecito qui)
- codice IATA di 2 lettere!
- anno di fondazione dopo il 1903, se vogliamo essere pedanti 1909
- sede (tecnicamente può cambiare, e vogliamo tenere lo storico)
Città
- nome ("Paperopoli" pare lecito qui)
- numero di abitanti (si spera più di 0? Immagina avere -10 abitanti, LOL)
- possibilmente una nazione?
Nazione
- nome
- codice ISO 3166-1
Osservazioni
- Non sono pedante sulla durata minima del volo, perché si suppone che la imposti un utente autorizzato (e autenticato!)
- Una città può avere 0 aeroporti, perché magari è la sede di una qualche compagnia
- Ho messo lo storico delle sedi legali delle compagnie per essere mettere più funzionalità possibili
UML
classDiagram
class Volo {
codice: (codice_IATA_compagnia: Stringa [A-Z]2, numero_di_volo: 1..9999)
durata: (ore: intero >= 0, minuti: intero 0..60)
ritardo: (ore: intero >= 0, minuti: intero 0..60)
}
class Aeroporto {
codice: (codice_IATA_aerporto: Stringa [A-Z]3)
nome: Stringa
}
class Compagnia {
codice: (codice_IATA_compagnia: Stringa [A-Z]2)
nome: Stringa
anno_di_fondazione: Intero >= 1903
}
class Compagnia["Compagnia aerea"]
class Citta {
nome: Stringa
numero_di_abitanti: Intero >= 0
}
class Citta["Città"]
class Nazione {
codice: (codice_ISO_3166-1: Stringa [A-Z]2)
nome: Stringa
}
class Sede {
data_inizio: Data
data_fine: Data
}
Volo "0..*" -- "1..1" Compagnia
Volo "0..*" -- "1..1" Aeroporto : parte_da
Volo "0..*" -- "1..1" Aeroporto : arriva_a
Aeroporto "0..*" -- "1..1" Citta : sta_in
Citta "0..*" -- "1..1" Nazione : sta_in
Compagnia "1..1" -- "1..*" Sede : compagnia_sede
Sede "1..1" -- "1..*" Citta : città_sede
Università 1
Requisiti
I dati di interesse per il sistema sono studenti, facoltà, professori e corsi.
-
Di ogni studente interessa conoscere il nome, il codice fiscale, il numero di matricola, la data di nascita, il luogo di nascita (città e regione), il corso di laurea a cui è iscritto (con l’anno di iscrizione), e gli insegnamenti di cui ha superato l’esame.
-
Dei professori interessa il nome, la data di nascita, il codice fiscale, il luogo di nascita e gli insegnamenti erogati.
-
Dei corsi di laurea interessa il nome e la o le facoltà di appartenenza. Di queste ultime interessa il nome.
-
Di ogni insegnamento interessa il codice, il nome, il numero di ore di lezione, e i corsi di laurea a cui appartiene.
Studente
- nome ("Paperopoli" pare lecito qui)
- codice fiscale (nome [A-Z]{3}, cognome [A-Z]{3}, anno [0-9]{2}, mese [A-Z]{1}, giorno [0-9]{2}, comune [A-Z][0-9]{3}, codice_controllo [A-Z]) per pedanti
- matricola (Stringa [0-9]{7})
- data di nascita (all my fellas be born after 1400?)
- luogo di nascita
- corso di laurea a cui è iscritto con anno di iscrizione (all my fellas be iscritti a più di un corso di laurea, ovvero 2 lo dice il Gov)
- insegnamenti superati con voto
(prima account su infostud, e solo dopo iscrizione ad un corso)
Insegnamento
- codice 100000..999999
- nome
- corsi di appartenenza
- ore di lezione intero > 0
Corso
- nome
- facoltà di appartenenza
Facoltà
- nome
Professore
- nome ("X Æ A-12" pare lecito qui)
- codice fiscale (stessa pappardella di sopra)
- data di nascita
- luogo di nascita
- insegnamenti erogati
UML
classDiagram
class Studente {
nome: Stringa
codice_fiscale: [A-Z]3[A-Z]3[0-9]2[A-Z][0-9]2[A-Z][0-9]3[A-Z]
matricola: Stringa [0-9]7
data_di_nascita: Data
}
class Citta {
nome: Stringa
}
class Citta["Città"]
class Regione {
nome: Stringa
codice: [A-Z]2
}
class Corso {
nome: Stringa
}
class Insegnamento {
codice: (codice_insegnamento: 100000..999999)
nome: Stringa
ore_di_lezione: intero >= 1
}
class Facolta {
nome: Stringa
}
class Facolta["Facoltà"]
class Professore {
nome: Stringa
data_di_nascita: Data
codice_fiscale: [A-Z]3[A-Z]3[0-9]2[A-Z][0-9]2[A-Z][0-9]3[A-Z]
}
Citta "0..*" -- "1..1" Regione : sta in
Studente "0..*" -- "1..1" Citta : nato a
Studente "0..*" -- "0..2" Corso : iscritto a
Studente "" -- "" Insegnamento : superato (voto 18..30, e la lode?)
Insegnamento "0..*" -- "0..*" Corso : in (potrei considerare 21..* a sinistra? Nah, la magistrale ne avra' di meno)
Corso "0..*" -- "1..1" Facolta : appartiene a
Professore "1..1" -- "0..*" Insegnamento : insegna
Voli Aerei 2
Requisiti
I dati di interesse per il sistema sono voli, compagnie aeree ed aeroporti.
Dei voli interessa rappresentare codice, durata, compagnia aerea ed aeroporti di partenza e arrivo.
Degli aeroporti interessa rappresentare codice, nome, città (con nome e numero di abitanti) e nazione.
Delle compagnie aeree interessa rappresentare nome, anno di fondazione, e la città in cui ha sede la direzione.
Un tipo particolare di voli sono voli charter.
Questi possono prevedere tappe intermedie in aeroporti.
Delle tappe intermedie di un volo charter interessa mantenere l’ordine con cui esse si susseguono (ad esempio, un certo volo che parte da “Milano Linate” e arriva a “Palermo Punta Raisi”, prevede tappe intermedie prima nell’aeroporto di Bologna e poi in quello di Napoli).
Dei voli charter interessa rappresentare anche il modello di velivolo usato.
Volo
- codice, composto dalle 2 lettere della compagnia, dal numero di volo (questo numero può variare da 1 a 4 cifre e serve a distinguere ogni volo gestito dalla compagnia aerea) {id}
- duarata
- compagnia aerea
- aeroporto di partenza
- aeroporto di arrivo
Aeroporto
- nome ("Paperopoli" pare lecito qui)
- codice, qui useremo il Il codice aeroportuale IATA [A-Z]{3} {id}
- città
- nazione
Compagnia aerea
- nome ("Paperopoli" pare lecito qui)
- codice IATA di 2 lettere {id}
- anno di fondazione dopo il 1903, se vogliamo essere pedanti 1909
- sede (città, non teniamo lo storico)
Voli
Città
- nome
- numero di abitanti >= 0
- nazione
Nazione
- nome
- codice ISO 3166-1, stringa lunga 2
Voli Charter
- tappe intermedie in aeroporti
- modello di velivolo
Tappe
- mantenere l'ordine con cui si susseguono
- “Milano Linate” e arriva a “Palermo Punta Raisi”, prevede tappe intermedie prima nell’aeroporto di Bologna e poi in quello di Napoli
UML
classDiagram
note "TIPI\nCodiceIATACompagnia = Stringa [A-Z]{2}\nCodiceIATAAeroporto = Stringa [A-Z]{3}\nCodiceIATAVolo = (codice_IATA: CodiceIATACompagnia, numero_di_volo: 1..9999)\nCodiceISO_3166-1_alpha-2: Stringa [A-Z]{2}"
class Volo {
durata: Durata
}
Volo : codice: CodiceIATAVolo {id}
class Charter {
modello: Stringa
}
class Aeroporto {
nome: Stringa
}
Aeroporto : codice: CodiceIATAAeroporto {id}
class Compagnia {
nome: Stringa
anno_di_fondazione: Intero
}
Compagnia : codice: CodiceIATACompagnia
class Compagnia["Compagnia aerea"]
class Citta {
nome: Stringa
numero_di_abitanti: Intero >= 0
}
class Citta["Città"]
class Nazione {
nome: Stringa
}
Nazione: codice: CodiceISO_3166-1_alpha-2 {id}
Volo "0..*" -- "1..1" Compagnia : gestito_da
Volo "0..*" -- "1..1" Aeroporto : parte_da
Volo "0..*" -- "1..1" Aeroporto : arriva_a
Aeroporto "0..*" -- "1..1" Citta : situato_a
Citta "0..*" -- "1..1" Nazione : si_trova_in
Compagnia "0..*" -- "1..1" Citta : ha_sede_a
Charter --|> Volo
Charter "0..*" -- "0..*" Aeroporto : tappa (numero > 0, univoco per ogni tappa del volo charter?)
Accademia 1
Requisiti
I dati di interesse per il sistema sono i docenti universitari, i progetti di ricerca e le attività dei docenti.
Di ogni docente interessa conoscere il nome, il cognome, la data di nascita, la matricola, la posizione universitaria (ricercatore, professore associato, professore ordinario) e i progetti ai quali partecipa.
Dei progetti interessa il nome, un acronimo, la data di inizio, la data di fine e i docenti che vi partecipano.
Un progetto è composto da molti Work Package (WP). Oltre al progetto a cui fa riferimento, del WP interessa sapere il nome, la data di inizio e la data di fine.
Il sistema deve permettere ai docenti di registrare impegni di diverso tipo.
Degli impegni interessa sapere il giorno in cui avvengono, la durata in ore e la tipologia di impegno con relativa motivazione.
Devo mettere gli ID!
Docenti
- nome
- cognome
- data di nascita
- matricola {id}
- posizione universitaria
- ricercatore
- professore associato
- professore ordinario
- progetti a cui partecipa (più di 1)
- impegni (più di 1?)
Progetti di ricerca
- nome
- acronimo [A-Z]{10}? {id?}
- data inizio
- data fine (opzionale? [0..1])
- i docenti che vi partecipano (più di 1)
Work Package
- nome
- progetto di cui fanno parte
- data inizio
- data fine (opzionale? [0..1])
Attività
- impegni di diverso tipo?
- giorno
- durata in ore
- motivazione
Tipologia
- Mi aspetto che il professore scelga la tipologia da un elenco prefissato dall'università, quindi lo tengo in una classe separata
UML
classDiagram
class Docente {
nome: Stringa
cognome: Stringa
data_di_nascita: Data
posizione: ["ricercatore", "professore associato", "professore ordinario"]
}
Docente : matricola: [A-Z0-9]{10} {id}
class Docente["Docente 👨🏫"]
class Progetto {
acronimo: [A-Z]+
}
class Progetto["Progetto di ricerca 🏗️"]
class WP {
nome: Stringa
data_inizio: Data
data_fine: Data [0..1]
}
class WP["Work Package 📦"]
class Attivita {
giorno: Data,
durata_ore: intero > 0,
}
class Attivita["Attività ⌚"]
class Tipologia {
nome: Stringa
}
Docente "0..*" -- "0..*" Progetto : partecipa_a
Docente "1..1" -- "0..*" Attivita : ha_un
WP "0..*" -- "1..1" Progetto : fa_parte_di
WP <|-- Progetto
Attivita "0..*" -- "1..1" Tipologia : di_tipo `(motivazione Stringa)`
Accademia 2
I dati di interesse per il sistema sono i docenti universitari, i progetti di ricerca e le attività dei docenti. Di ogni docente interessa conoscere il nome, il cognome, il luogo e la data di nasci- ta, la matricola e la posizione universitaria (una tra: ricercatore, professore associato, professore ordinario). Dei progetti interessa il nome, un acronimo, la data di inizio, la data di fine e i docenti che vi partecipano. Un progetto è composto da molti Work Package (WP). Oltre al progetto a cui fa riferimento, del WP interessa sapere il nome, la data di inizio e la data di fine. Il sistema deve permettere ai docenti di registrare impegni di diverso tipo tra: as- senza (per chiusura universitaria, malattia, gravidanza, etc.), attività legate a impegni istituzionali (didattica, ricerca, missione, consiglio di dipartimento, consiglio di area di- dattica, etc.), attività legate a impegni progettuali (Ricerca e Sviluppo, Dimostrazione, Management, etc.). Degli impegni interessa sapere il giorno in cui avvengono, la durata e la tipologia di impegno con relativa motivazione. Si noti che alcuni impegni (ad es., impegno per didattica oppure alcuni tipi di assenza) possono occupare solo parte di una giornata lavorativa, pertanto la loro durata va misurata in giorni; altri impegni ed altre tipologie di assenza (ad es., assenza per malattia) occupano intere giornate, e la loro durata, dunque, va misurata in giorni.
Officine 1
I dati di interesse per il sistema sono quelli relativi alle officine della catena, i relativi dipendenti e direttori, e quelli relativi alle riparazioni dei veicoli.
Di ogni officina della catena interessano il nome, l’indirizzo, il numero di dipendenti, i dipendenti con il relativo numero di anni di servizio ed il direttore.
Dei dipendenti e dei direttori interessano il nome, il codice fiscale, l’indirizzo e il numero di telefono; inoltre dei direttori interessa anche la data di nascita.
Per quanto riguarda le riparazioni dei veicoli, sono dati di interesse il codice, il vei- colo (modello, tipo, targa, anno di immatricolazione e proprietario), la data ed ora di accettazione e quella di riconsegna (per le riparazioni terminate).
Infine, dei proprietari dei veicoli interessano nome, codice fiscale, indirizzo e telefono.
Travel to the Moon
Requisiti
-
Requisiti sulle crociere: 1.1. codice 1.2. data di inizio 1.3. data di fine 1.4. nave utilizzata (v. req. 2) 1.5. itinerario (v. req. 4) 1.6. il tipo, uno tra: 1.6.1. luna di miele, di cui interessa un sottotipo tra: 1.6.1.1. tradizionali (# dest. romantiche >= # dest. divertenti) (v. req. 3) 1.6.1.2. alternative (altrimenti) 1.6.2. per famiglie, di cui interessa: 1.6.3. se adatte ai bambini (booleano)
-
Requisiti sulle navi 2.1. nome 2.2. comfort (3..5) 2.3. capienza (max)
-
Requisiti sui porti: 3.1. nome 3.2. continente ({"Africa", "Asia", "Europa", etc...}) 3.3. posti da vedere (v. req. 5) 3.4. tipo, almeno uno tra: 3.4.1. romantico 3.4.2. divertente 3.5 un insieme di posti da vedere (v. req. 5)
-
Requisiti sugli itinerari: di ogni itinerario interessa 4.1. nome 4.2. sequenza ordinata di elementi (tappe), di cui interessa: 4.2.1. porto (v. req. 3) 4.2.2. arrivo: 4.2.2.1. il numero d'ordine del giorno (rispetto alla data di inizio della crociera) 4.2.2.2. ora 4.2.3. ripartenza
4.2.3.1. il numero d'ordine del giorno (rispetto alla data di inizio della crociera) 4.2.3.2. ora -
Requisiti sui posti da vedere: 5.1. nome 5.2. descrizione 5.3. fascia consigliata 5.3.1. giorno 5.3.2. ora inizio 5.3.3. ora fine
-
Requisiti clienti 6.1. nome 6.2. cognome 6.3. età 6.3. indirizzo: (nome: Stringa, civico: numero, Città: Stringa, Regione: Stringa, Paese: Stringa) 6.4. può prenotare crociere (v. req. 7)
-
Requisiti prenotazioni 6.1. istante di prenotazione (DataOra?) 6.2. crociera prenotatata (v. req. 1) 6.3. posti prenotati (Intero > 0)
UML
classDiagram
class Nave {
nome: Stringa
conformt: 3..5
capienza: Intero > 0
}
class Destinazione {
nome: Stringa
tipo: [Romantico, Divertente] [1..2]
}
class Continente {
nome: Stringa
}
class PostoDaVedere {
nome: Stringa
}
Destinazione "0..*" -- "1..1" Continente : "porto_cont"
Destinazione "0..*" -- "0..*" PostoDaVedere : "porto_post"
Requisiti 1 e 4 (crociere e itinerari)
Algoritmi II
Un grafo è una coppia dove è un insieme di vertici ed un insieme di nodi; un grafo si dice
- semplice se ogni coppia di nodi è collegata con al massimo un arco, e non ci sono cappi
- diretto se gli archi sono orientati
- connesso se ogni coppia di nodi è collegata da una passeggiata
- fortemente connesso se per ogni coppia di vertici esiste un cammino da a e viceversa
Due nodi si dicono adiacenti () se sono collegati da un arco, e l'arco si dice incidente rispetto ai due nodi
Rappresentazione
Un grafo si può rappresentare tramite matrice di adiacenza o lista di adiacenza
Matrice di adiacenza
Siano i vertici del grafo, possiamo rappresentare il grafo come una matrice tale che
| ... | ||||
| 0 | 1 | ... | 0 | |
| 1 | 0 | ... | 1 | |
| ... | ... | ... | ... | ... |
| 0 | 1 | ... | 0 |
Per verificare se il costo è la dimensione della matrice è con
Lista di adiacenza
Siano i vertici del grafo, possiamo indicare per ogni nodo l'insieme dei suoi vicini
| ... | |
Per verificare se il costo è la dimensione della matrice è , con
Teoremi
Definizione
Una passeggiata in un grafo è definita come una sequenza dove collega a
Definizione
Una passeggiata si dice euleriana se attraversa ogni arco del grafo esattamente una volta
Teorema di Eulero
una passeggiata euleriana il grafo è connesso ed esistono al massimo 2 vertici di grado dispari
Definizione
Un cammino è una passeggiata che non ripete vertici (quindi neanche archi)
Definizione
Un ciclo in un grafo è un sottografo connesso con ogni vertice di grado 2
Osservazione
Se una passeggiata da a un cammino da a
si dimostra con l'algoritmo
DFS (depth first search)
#![allow(unused)] fn main() { dfs(graph, y, visited) } } } fn dfs_iterative(graph: &[Vec<usize>], x: usize) -> Vec<bool> { let mut stack = Vec::from([x]); let mut visited = vec![false; graph.len()]; let mut adjacent = vec![0; graph.len()]; while let Some(&x) = stack.last() { if let Some(&y) = graph[x].get(adjacent[x]) { if !visited[y] { stack.push(y); visited[y] = true; } adjacent[x] += 1; } else { stack.pop(); }
Dimostrazione correttezza: bisogna dimostrare che
se un cammino da a
per assurdo, supponiamo che
| ... | ||||
| ... | ... | ... |
Sia un indice
è stato inserito nello stack ma se stack e stack l'algoritmo non è stato eseguito correttamente (contraddizione!)
TODO: complessità
Definizione
L'albero di visita è un sottografo composto dagli archi che usiamo per raggiungere i vertici nuovi non ancora visitati
- è connesso
- è aciclico
Definizione
L'albero di visita di un grafo diretto è detto arborescenza
- diretto
- ogni arco orientato dalla radice alle foglie
Se è un graffo connesso contiene tutti i nodi del grafo
Se non è connesso è il componennte che contiene
Ordine topologico
Consideriamo un progetto diviso in task, con dipendenze fra i vari task (Es. va eseguito dopo e , e dopo ; in questo caso l'ordine sarebbe )
Indicando i vertici con e gli archi con se dipende da , una programmazione dei task corrisponde ad un ordine dei vertici con tutti gli archi da destra verso sinistra
Se il grafo ha un ciclo (diretto), non è possibile dare un ordine topologico
Dimostrazione
Suppponiamo per assurdo che esiste un tale ordine, allora uno dei vertici deve essere per forza l'ultimo nell'ordine; ma essendo ciclico esiste un arco che va da sinistra verso destra da uno dei vertici "centrali" della sequenza all'ultimo vertice, quindi tale ordine non esiste.
Definizione
Un grafo diretto ha un ordine topologico se un ordine deivertici con tutti gli ordini degli archi da destra verso sinistra
Proposizione
Se un grafo diretto ha la proprietà che ogni vertice ha almeno un arco uscente un ciclo
stessa dimostrazione dell'algoritmo del primo giorno: se ogni vertice ha un arco uscente e i vertici sono finiti, alora prima o poi dovrà tornare... (creare un ciclo)
L'implicazione non è vera!
Corollario
Se \notexists un ciclo un nodo senza archi uscenti
Soluzione naive
TODO: algoritmo per trovare l'ordine topologico!
Soluzione con DFS
Esercizi
Ciclo in un grafo
inputun grafooutputun ciclo un grafo (come elenco di vicini)complessità
#![allow(unused)] fn main() { use std::collections::VecDeque; pub mod practice; use practice::path; fn find_cycle(graph: &[Vec<usize>], mut x: usize) -> Vec<usize> { let mut cycle = vec![]; let mut visited = vec![false; graph.len()]; let mut z = x; while !visited[x] { cycle.push(x); visited[x] = true; let next = if graph[x][0] == z { 1 } else { 0 }; z = x; x = graph[x][next]; } cycle.into_iter().skip_while(|&y| y != x).collect() } fn does_path_exist(graph: &[Vec<usize>], x: usize, y: usize) -> bool { }
Cammino da a
inputun grafo eoutputcomplessità
#![allow(unused)] fn main() { dfs(graph, x, &mut visited); visited[y] } fn dfs(graph: &[Vec<usize>], x: usize, visited: &mut Vec<bool>) { visited[x] = true; for &y in &graph[x] { }
#![allow(unused)] fn main() { dfs(graph, y, visited) } } } fn dfs_iterative(graph: &[Vec<usize>], x: usize) -> Vec<bool> { let mut stack = Vec::from([x]); let mut visited = vec![false; graph.len()]; let mut adjacent = vec![0; graph.len()]; while let Some(&x) = stack.last() { if let Some(&y) = graph[x].get(adjacent[x]) { if !visited[y] { stack.push(y); visited[y] = true; } adjacent[x] += 1; } else { stack.pop(); }
#![allow(unused)] fn main() { fn path(graph: &Vec<Vec<usize>>, x: usize, y: usize) -> bool { dfs_iterative(graph, x)[y] } }
Componenti di
inputun grafooutputl'elenco di archi in avanti, indietro e di attraversamentocomplessità
#![allow(unused)] fn main() { } visited } pub fn find_components(graph: &[Vec<usize>]) -> Vec<usize> { let mut components = vec![0; graph.len()]; let mut component = 1; for x in 0..graph.len() { if components[x] == 0 { dfs_components(graph, x, &mut components, component); component += 1; } } components } fn dfs_components(graph: &[Vec<usize>], x: usize, components: &mut Vec<usize>, component: usize) { components[x] = component; for &y in &graph[x] { if components[y] == 0 { dfs_components(graph, y, components, component) } } } }
Classificazione archi
inputun grafooutputle componenti dicomplessità